
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 정렬
- 프로그래머스
- 그래프
- isdigit()
- Knowledge graph
- 코테
- Python
- LSTM
- kg
- bfs
- isalpha()
- 그래프 탐색
- Dynamic Programming
- 동적 프로그래밍
- 파이썬
- 우선순위 큐
- find()
- isnumeric()
- Deque
- DP
- 추천시스템
- knowledge
- Algorithm
- explainable recommendation
- Recommendation
- 알고리즘
- isalnum()
- 자료구조
- 백준
- Stack
- Today
- Total
데린이 고인물되기
[TIL] 250607 - 그래프 본문
바킹독님의 그래프 강의를 참고해 파이썬 버전으로 작성했습니다.
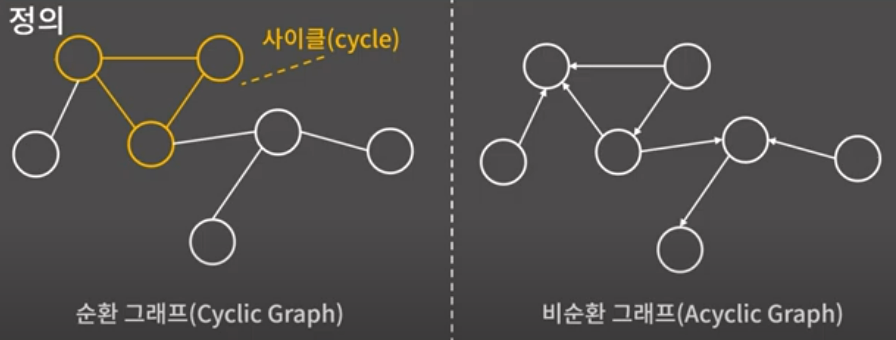
사이클
임의의 한 점에서 출발해 자기 자신으로 돌아올 수 있는 경로. 그래프 안에 사이클이 하나라도 있으면 순환 그래프, 하나도 없으면 비순환 그래프
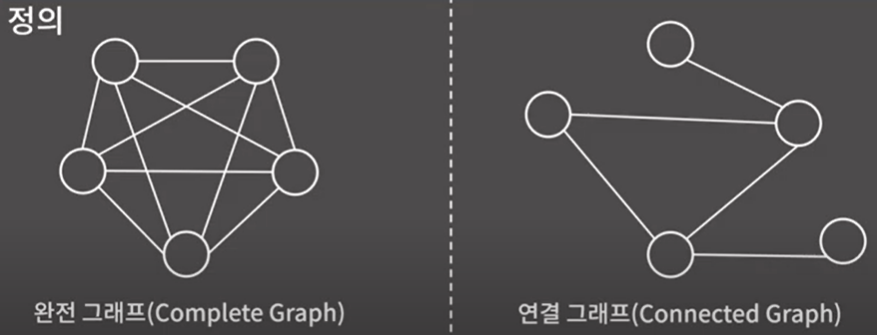
완전 그래프 vs 연결 그래프
완전 그래프 : 모두 서로 다른 두 정점 쌍이 간선으로 연결되 그래프
연결 그래프 : 임의의 두 정점 사이에 경로가 항상 존재하는 그래프
간과하기 쉬운 그래프 예시

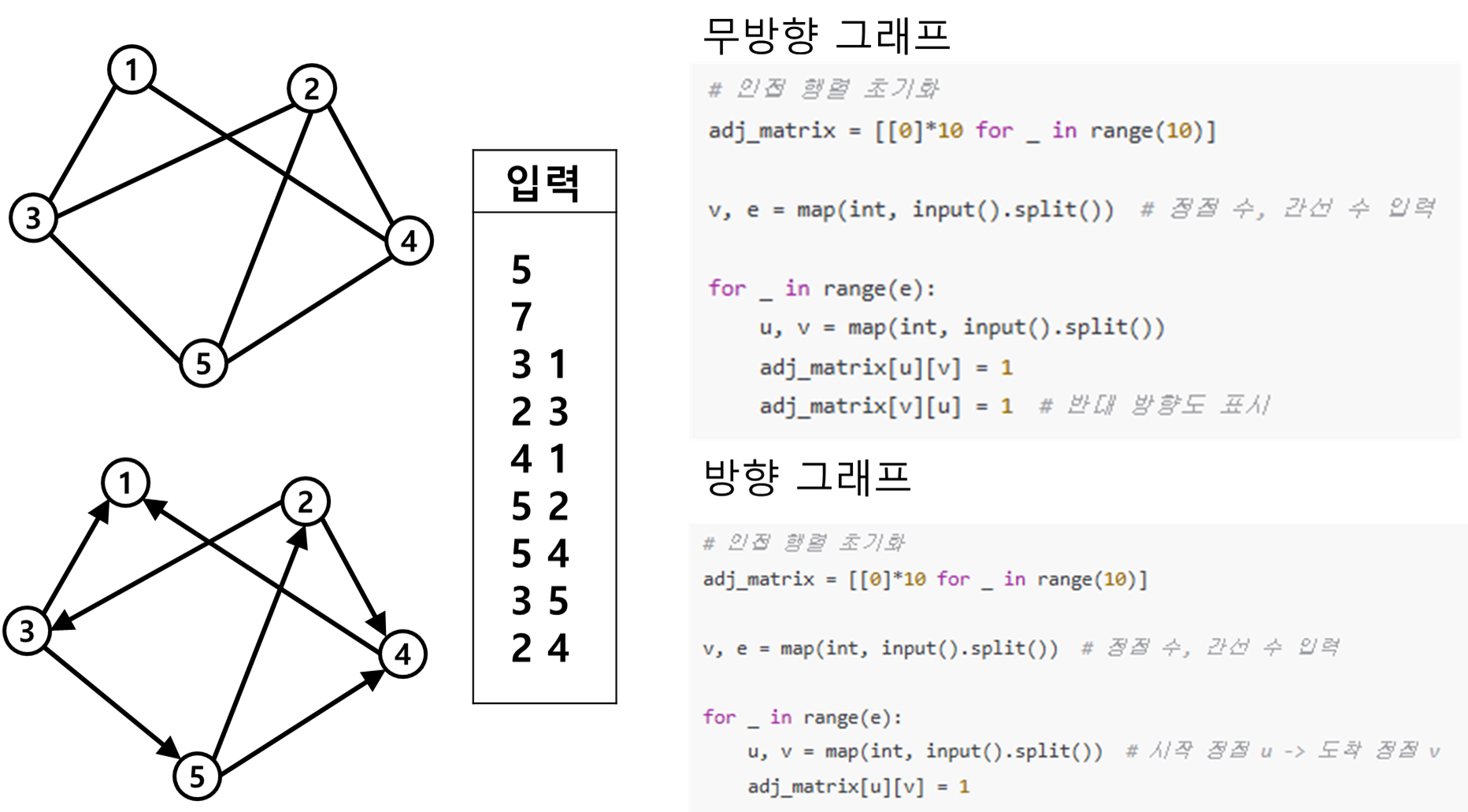
그래프를 코드로 표현하는 법
1. 인접행렬
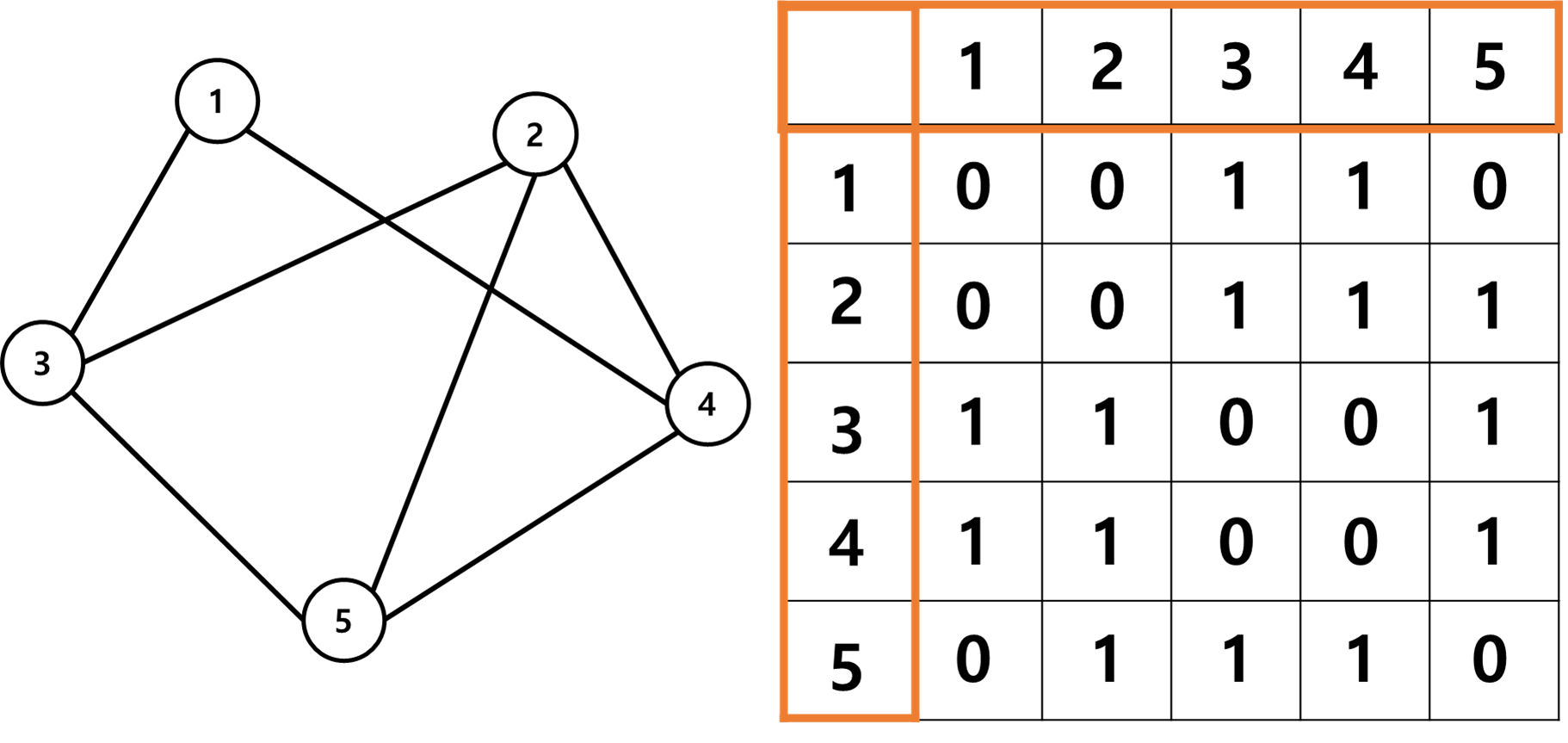
- 노드 사이에 edge 가 있으면 1, 아니면 0으로 표현
- 무방향 그래프의 경우 인접행렬이 대칭

- 방향그래프의 경우 인접행렬이 대칭이 아님
- 노드 2에서 노드 3으로 가는 엣지가 있는 경우 인접행렬의 (2,3) 의 위치에 1이 있는 형태
인접행렬 표현 구현
- 보통 노드의 경우 관례적으로 1부터 노트 번호를 매김
2. 인접 리스트
- 인접 행렬과 비교했을 때 정점이 많고 간선은 상대적으로 작은 상황에서 공간을 절약할 수 있는 방법
- 경우에 따라 인접 행렬로는 저장이 불가능하고 반드시 인접 리스트를 써야하는 경우가 있음
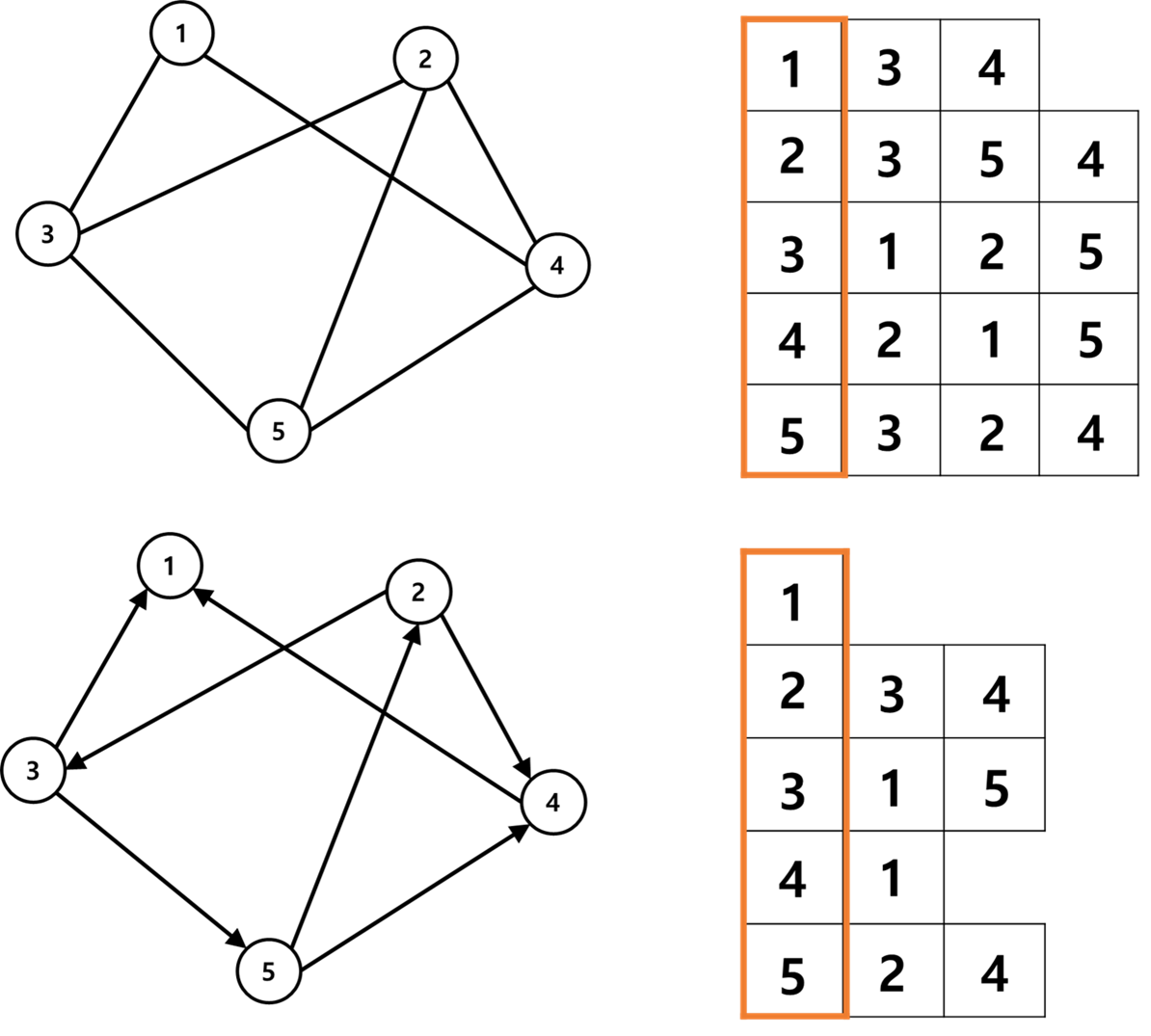
인접 리스트 표현 구현
- 무향뱡 그래프
# 인접 리스트 초기화
adj = [[] for _ in range(10)] # 노드 번호가 1번부터 시작할 경우
v, e = map(int, input().split())
for _ in range(e):
u, w = map(int, input().split())
adj[u].append(w)
adj[w].append(u) # 반대 방향도 추가!
- 방향 그래프
# 인접 리스트 초기화
adj = [[] for _ in range(10)] # 노드 번호가 1번부터 시작할 경우
v, e = map(int, input().split()) # 정점 수 v, 간선 수 e
for _ in range(e):
u, w = map(int, input().split()) # u -> w 방향 간선
adj[u].append(w)| 구분 | 인접 행렬 (Adjacency Matrix) | 인접 리스트 (Adjacency List) |
| 공간 복잡도 | O(V²) | O(V + E) |
| 두 정점 u, v가 연결되어 있는지 확인 시간 | O(1) | O(min(deg(u), deg(v))) |
| 정점 v와 연결된 모든 정점 확인 시간 | O(V) | O(deg(v)) |
| 효율적인 상황 | - 두 정점의 연결 여부를 자주 확인할 때 - 간선 수 E가 정점 수 V²에 가까울 때 (밀집 그래프) |
- 특정 정점에 연결된 정점들을 자주 확인할 때 - 간선 수 E가 정점 수 V보다 훨씬 작을 때 (희소 그래프) |
- 정점 u, v가 연결되어 있는지 확인하는 시간
- 인접 행렬 (O(1))
- 그냥 adj_matrix[u][v]를 바로 보면 됨 → 배열 인덱스 접근 = 상수 시간
- 인접 리스트 (O(min(deg(u), deg(v))))
- adj[u] 또는 adj[v] 중 더 짧은 리스트를 골라서 일일이 선형 탐색
- 인접 행렬 (O(1))
- 정점 v와 연결된 모든 정점 확인 시간
- 인접 행렬 (O(V))
- adj[v][0]부터 adj[v][V-1]까지 전부 확인해야 함
- 연결된 게 몇 개든 상관없이 V칸 전부 확인 → O(V)
- 인접 리스트 (O(deg(v)))
- 연결된 정점만 리스트에 있으므로, 그냥 리스트 하나 순회하면 됨 → O(deg(v))
- 인접 행렬 (O(V))
BFS
- BFS = 그래프에서 너비를 우선으로 방문하는 알고리즘
- 이전에는 BFS를 다차원 행렬에서 사용하는 법을 알아봤는데, 저 행렬이 오른쪽을 그래프로 표현된다고 생각하면 됨

- 그래프에서 BFS 방법을 글로 남기면 아래와 같음
1. 시작하는 정점을 큐에 넣고 방문했다는 표시를 남김
2. 큐에서 정점을 꺼내어 그 정점과 연결된 모든 정점들에 대해 3번을 진행
3. 해당 정점을 이전에 방문했다면 아무 것도 하지 않고, 처음으로 방문했다면 방문했다는 표시를 남기고 해당 값을 큐에 삽입
4. 큐가 빌 때까지 2번을 반복
모든 정점이 큐에 최대 1번씩 들어가므로 인접 리스트에서 O(V+E), 인접 행렬에서 O(V²)의 시간복잡도.
- 다차원 배열에서는 2번 과정에서 상하좌우 인접한 칸을 확인했다면,
- 그래프에서는 edge로 연결된 node를 본다는 차이만 있음
- 그래프에서도 BFS를 이용하면 두 노드 사이의 최단 경로를 찾을 수 있음

- 단, 이건 모든 간선의 길이가 같은 경우 사용할 수 있음.
- 모든 간선의 길이가 다르다면, 플로이드나 다익스트라 같은 다른 알고리즘을 사용해야 함
인접 리스트 방식으로 저장된 연결 그래프에서 BFS 진행하는 코드(예시 코드 1)
- 연결 그래프에서의 순회
from collections import deque
# 인접 리스트
adj = [[] for _ in range(10)] # 이미 인접 리스트에 값은 채워져있다고 가정하고 밑에 코드 진행함
# 예시 :
#adj = [
# [], # 0번 정점 (사용 안 함)
# [2, 3], # 1번 정점은 2, 3과 연결됨
# [4], # 2번 정점은 4와 연결됨
# [4], # 3번 정점은 4와 연결됨
# [5], # 4번 정점은 5와 연결됨
# [], # 5번 정점은 연결 없음
# [], # 6~9번 정점도 연결 없음
# [],
# [],
# []
#]
# 방문 여부 배열
vis = [False] * 10
def bfs():
q = deque()
q.append(1) # 시작 정점
vis[1] = True # 방문 표시
while q:
cur = q.popleft()
for nxt in adj[cur]: # 현재 노드에 연결된 모든 인접 노드 탐색
if vis[nxt]:
continue
q.append(nxt)
vis[nxt] = True
BFS를 이용한 최단 거리 계산 코드(예시 코드 2)
- dist를 -1로 초기화 한 뒤에 dis 배열이 -1인지 아닌지를 가지고 방문 여부를 판단하면 vis 배열을 별도로 둘 필요가 없음
from collections import deque
# 인접 리스트
adj = [[] for _ in range(10)]
# 거리 배열 (모두 -1로 초기화)
dist = [-1] * 10
def bfs():
q = deque()
q.append(1) # 시작 정점
dist[1] = 0 # 시작 정점 거리 0
while q:
cur = q.popleft()
for nxt in adj[cur]:
if dist[nxt] != -1:
continue
q.append(nxt)
dist[nxt] = dist[cur] + 1
연결 그래프가 아닐 때 순회 (예시 코드 3)

왼쪽 같이 연결 그래프가 아닌경우 예시 코드 1 처럼 코드를 짜면 1,2,3,4 노드만 방문을 하고 5,6 노드는 방문을 하지 않음.
이 경우 아래처럼 코드를 작성하면 됨
from collections import deque
v = 9 # 정점 개수
adj = [[] for _ in range(10)]
vis = [False] * 10
def bfs():
for i in range(1, v + 1):
if vis[i]:
continue
q = deque()
q.append(i)
vis[i] = True
while q:
cur = q.popleft()
for nxt in adj[cur]:
if vis[nxt]:
continue
q.append(nxt)
vis[nxt] = True- for 문으로 방문하지 않은 노드가 있으면 방문을 해주는 방식을 추가해서 연결 그래프가 아니라도 모든 노드를 다 방문할 수 있도록 함
DFS
- 다차원 배열에서 DFS를 공부할 때는, BFS와 모든게 동일하지만, BFS에서는 deque를 사용했다면 DFS에서는 stack을 사용한다는 차이점만 있었음
- 그래프에서도 마찬가지임
연결 그래프에서의 순회, 비재귀 ( 예시 코드 1 )
adj = [[] for _ in range(10)] # 인접 리스트
vis = [False] * 10 # 방문 여부 배열
def dfs():
stack = []
stack.append(1)
vis[1] = True
while stack:
cur = stack[-1] # stack top
stack.pop()
for nxt in adj[cur]:
if vis[nxt]:
continue
stack.append(nxt)
vis[nxt] = True
연결 그래프에서의 순회, 재귀( 예시 코드 2 )
- DFS는 재귀를 이용해서 구현을 할 수 있음
adj = [[] for _ in range(10)] # 인접 리스트
vis = [False] * 10 # 방문 여부 배열
def dfs(cur):
vis[cur] = True
for nxt in adj[cur]:
if vis[nxt]:
continue
dfs(nxt)스택 메모리 제한이 별도로 있는 경우, 재귀적으로 구현하는 것보다는 예시 코드 1처럼 stack으로 구현해야 함
재귀 DFS와 비재귀 DFS의 동작 차이

재귀적인 방식은 실제 방문할 때 방문 표시를 남기는 반면, 비재귀적 방식은 방문하기 전에 아직 방문하지 않은 곳을 발견하면 그 때 방문 표시를 남겨버림.
일반적으로 생각하는 방문 순서는 재귀를 이용해 구현한 DFS의 방문 순서와 일치함.
이런 순서로 방문하는 코드를 구현해야할 경우 비재귀 방식으로 DFS를 구현하면 안됨. 근데 스택 메모리 때문에 재귀 방식으로 구현도 어려운 경우가 있음. 그래서 필요한게 예시 코드 3 ⬇️
연결 그래프에서의 순회, 비재귀 2 ( 예시 코드 3 )
adj = [[] for _ in range(10)] # 인접 리스트
vis = [False] * 10 # 방문 여부 배열
def dfs():
stack = []
stack.append(1) # 시작 정점
while stack:
cur = stack[-1] # top
stack.pop()
if vis[cur]:
continue
vis[cur] = True
for nxt in adj[cur]:
if vis[nxt]:
continue
stack.append(nxt)우리가 관념적으로 생각하는 DFS와 동일하게 동작하도록 비재귀 방식으로 구현한 코드.
스택에 넣을 때 방문 표시를 남기는 예시 코드 1과 달리, 스택에서 노드를 뺄 때 방문 표시를 남김
⬇️ 예시 코드 1
adj = [[] for _ in range(10)] # 인접 리스트
vis = [False] * 10 # 방문 여부 배열
def dfs():
stack = []
stack.append(1)
vis[1] = True
while stack:
cur = stack[-1] # stack top
stack.pop()
for nxt in adj[cur]:
if vis[nxt]:
continue
stack.append(nxt)
vis[nxt] = True연습문제
나의 답
# dfs 로 한번 쭉 돌았을 때 visited에 방문 안한 노드가 잇으면 그걸로 다시 돌고 반복하면서
# 연결 요소 개수 세어주기
import sys
input = sys.stdin.readline
sys.setrecursionlimit(10**6)
e, v = map(int, input().split())
board = [[] for _ in range(e+1)]
for _ in range(v):
u,v = map(int, input().split())
board[u].append(v)
board[v].append(u)
visited = [False]*(e+1)
answer = 0 # connected component 수
def dfs(start_node):
s = []
s.append(start_node)
visited[start_node] = True
while s:
cur = s[-1]
s.pop()
for next in board[cur]:
if visited[next]:
continue
s.append(next)
visited[next] = True
for i in range(1, e+1):
if visited[i]:
continue
dfs(i)
answer += 1
print(answer)# bfs 로 한번 쭉 돌았을 때 visited에 방문 안한 노드가 잇으면 그걸로 다시 돌고 반복하면서
# 연결 요소 개수 세어주기
import sys
input = sys.stdin.readline
from collections import deque
sys.setrecursionlimit(10**6)
e, v = map(int, input().split())
board = [[] for _ in range(e+1)]
for _ in range(v):
u,v = map(int, input().split())
board[u].append(v)
board[v].append(u)
visited = [False]*(e+1)
answer = 0 # connected component 수
def bfs(start_node):
q = deque()
q.append(start_node)
visited[start_node] = True
while q:
cur = q.popleft()
for next in board[cur]:
if visited[next]:
continue
q.append(next)
visited[next] = True
for i in range(1, e+1):
if visited[i]:
continue
bfs(i)
answer += 1
print(answer)# 재귀 dfs 로 한번 쭉 돌았을 때 visited에 방문 안한 노드가 잇으면 그걸로 다시 돌고 반복하면서
# 연결 요소 개수 세어주기
import sys
input = sys.stdin.readline
from collections import deque
sys.setrecursionlimit(10**6)
e, v = map(int, input().split())
board = [[] for _ in range(e+1)]
for _ in range(v):
u,v = map(int, input().split())
board[u].append(v)
board[v].append(u)
visited = [False]*(e+1)
answer = 0 # connected component 수
def bfs(start_node):
visited[start_node] = True
for next_node in board[start_node]:
if visited[next_node]:
continue
bfs(next_node)
for i in range(1, e+1):
if visited[i]:
continue
bfs(i)
answer += 1
print(answer)
영상 답
import sys
from collections import deque
input = sys.stdin.readline
n, m = map(int, input().split()) # 정점 수 n, 간선 수 m
adj = [[] for _ in range(n + 1)] # 인접 리스트 초기화
# 간선 입력 처리
for _ in range(m):
u, v = map(int, input().split())
adj[u].append(v)
adj[v].append(u) # 무방향 그래프이므로 양방향
vis = [False] * (n + 1) # 방문 여부 리스트
num = 0 # 연결 요소 수
# BFS를 통한 연결 요소 탐색
for i in range(1, n + 1):
if vis[i]:
continue
num += 1
q = deque()
q.append(i)
vis[i] = True
while q:
cur = q.popleft()
for nxt in adj[cur]:
if vis[nxt]:
continue
q.append(nxt)
vis[nxt] = True
print(num)
나의 답
from collections import deque
node_num, edge_num, start_node = map(int, input().split())
adj = [[] for _ in range(node_num+1)]
for i in range(1,edge_num+1):
n,v = map(int,input().split())
adj[n].append(v)
adj[v].append(n)
for i in range(1,node_num+1):
adj[i].sort()
visited_dfs = [False]*(node_num+1)
dfs_list = []
bfs_list = []
def dfs(start_node):
visited_dfs[start_node] = True
dfs_list.append(start_node)
for next_node in adj[start_node]:
if visited_dfs[next_node]:
continue
dfs(next_node)
def bfs(start_node):
visited = [False]*(node_num+1)
q = deque()
q.append(start_node)
bfs_list.append(start_node)
visited[start_node] = True
while q:
cur = q.popleft()
for next_node in adj[cur]:
if visited[next_node]: # 방문한적 있는 노드면
continue
q.append(next_node)
visited[next_node] = True
bfs_list.append(next_node)
dfs(start_node)
bfs(start_node)
print(' '.join(map(str,dfs_list)))
print(' '.join(map(str,bfs_list)))
영상 답
from collections import deque
# 입력
n, m, st = map(int, input().split())
adj = [[] for _ in range(n + 1)]
for _ in range(m):
u, v = map(int, input().split())
adj[u].append(v)
adj[v].append(u)
# 번호가 작은 정점부터 방문하도록 정렬
for i in range(1, n + 1):
adj[i].sort()
########### 비재귀 DFS ###########
def dfs1(start):
visited = [False] * (n + 1)
stack = [start]
result = []
while stack:
cur = stack.pop()
if visited[cur]:
continue
visited[cur] = True
result.append(cur)
# 스택은 후입선출이므로 인접 정점을 역순으로 push
for nxt in reversed(adj[cur]):
if not visited[nxt]:
stack.append(nxt)
print(' '.join(map(str, result)))
############ 재귀 DFS ###########
def dfs2(cur, visited, result):
visited[cur] = True
result.append(cur)
for nxt in adj[cur]:
if not visited[nxt]:
dfs2(nxt, visited, result)
############ BFS ###########
def bfs(start):
visited = [False] * (n + 1)
q = deque()
q.append(start)
visited[start] = True
result = []
while q:
cur = q.popleft()
result.append(cur)
for nxt in adj[cur]:
if not visited[nxt]:
q.append(nxt)
visited[nxt] = True
print(' '.join(map(str, result)))
# 실행
visited_dfs2 = [False] * (n + 1)
dfs2_result = []
dfs2(st, visited_dfs2, dfs2_result)
print(' '.join(map(str, dfs2_result)))
bfs(st)'Algorithm > 정리' 카테고리의 다른 글
| [TIL] 250628 - 그리디 (Greedy) (0) | 2025.06.29 |
|---|---|
| [TIL] 250608 - 트리 (1) | 2025.06.08 |
| [TIL] 250605 - 완전 탐색 가능 여부 판단 기준(시간 복잡도) (0) | 2025.06.05 |
| [TIL] 250531 - 이분탐색(Lower Bound / Upper Bound / Custom Bound) (0) | 2025.05.31 |
| [TIL] 250529 - 파이썬 itertools.permutations 사용법 (0) | 2025.05.29 |
