
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 추천시스템
- 코테
- kg
- 그래프 탐색
- isnumeric()
- 그래프
- 프로그래머스
- Dynamic Programming
- LSTM
- 백준
- knowledge
- isalnum()
- bfs
- Knowledge graph
- 정렬
- DP
- Deque
- 자료구조
- explainable recommendation
- 알고리즘
- Python
- 파이썬
- 우선순위 큐
- isdigit()
- isalpha()
- Algorithm
- Stack
- Recommendation
- find()
- 동적 프로그래밍
Archives
- Today
- Total
데린이 고인물되기
[TIL] 250608 - 트리 본문
반응형

- 트리도 node와 edge로 이루어진 자료구조로, 그래프의 한 종류
정의와 성질
- 트리는 무방향이면서 사이클이 없는 연결 그래프(Undirected acyclic connected graph)
- = 연결 그래프이면서 임의의 간선을 제거하면 연결 그래프가 아니게 되는 그래프
- = 임의의 두 점을 연결하는 simple path(정점이 중복해서 나오지 않는 경로)가 유일한 그래프
- = V개의 정점을 가지고 V-1개의 간선을 가지는 연결 그래프
- = 사이클이 없는 연결 그래프이면서 임의의 간선을 추가하면 사이클이 생기는 그래프
- = V개의 정점을 가지고 V-1개의 간선을 가지는 Acyclic(=사이클이 없는) 그래프
트리에서의 BFS

- 트리에서는 BFS의 과정 속에서 자신의 자식들을 전부 큐에 넣어주기만 하면 됨. 즉, 자신과 이웃한 정점들에 대해 부모만 빼고 나머지를 큐에 넣으면 됨.
- ➡️방문 여부를 표시하는 vis 배열을 쓰지 않고 그냥 부모 노드가 누구인지만 저장하고 있으면 됨. 부모 노드의 정보는 BFS를 도릴면서 자식 노드를 큐에 넣을 때 채워줄 수 있음.
BFS 부모 배열 채우기( 예시 코드 1)
from collections import deque
adj = [[] for _ in range(10)] # 인접 리스트
p = [0] * 10 # 부모 노드 기록용 배열
# 처음 루트의 부모는 자연스럽게 0이 되는거임
def bfs(root):
q = deque()
q.append(root)
while q:
cur = q.popleft()
for nxt in adj[cur]:
if p[cur] == nxt: # 부모로 돌아가는 간선 무시
continue
q.append(nxt)
p[nxt] = cur
BFS 부모와 depth 배열 채우기 ( 예시 코드 2 )
- 자식의 depth는 부모의 depth + 1 임을 이용하면 됨
from collections import deque
adj = [[] for _ in range(10)] # 인접 리스트
p = [0] * 10 # 부모 노드 저장
depth = [0] * 10 # 깊이 저장
def bfs(root):
q = deque()
q.append(root)
while q:
cur = q.popleft()
for nxt in adj[cur]:
if p[cur] == nxt: # 부모 방향 간선이면 스킵
continue
q.append(nxt)
p[nxt] = cur
depth[nxt] = depth[cur] + 1
트리에서의 DFS
- DFS에서도 시작 노드를 잡으면, 그 노드를 root로 가정하는 것이 편함

- 위와 같은 트리에서 DFS를 돌리면 $1 \rightarrow 2 \rightarrow 5 \rightarrow 3 \rightarrow 4 \rightarrow 6 \rightarrow 7 \rightarrow 8$ 순으로 방문함
DFS 부모와 depth 배열 채우기, 비재귀( 예시 코드 1 )
adj = [[] for _ in range(10)] # 인접 리스트
p = [0] * 10 # 부모 노드 저장
depth = [0] * 10 # 깊이 저장
def dfs(root):
stack = [root]
while stack:
cur = stack.pop()
for nxt in adj[cur]:
if p[cur] == nxt: # 부모로 가는 간선 제외
continue
stack.append(nxt)
p[nxt] = cur
depth[nxt] = depth[cur] + 1- BFS 코드에서 큐를 stack으로만 바꾸면 됨
DFS 부모와 depth 배열 채우기, 재귀 ( 예시 코드 2 )
adj = [[] for _ in range(10)] # 인접 리스트
p = [0] * 10 # 부모 노드 저장
depth = [0] * 10 # 깊이 저장
def dfs(cur):
for nxt in adj[cur]:
if p[cur] == nxt:
continue
p[nxt] = cur
depth[nxt] = depth[cur] + 1
dfs(nxt)
DFS 단순 순회, 재귀 ( 예시 코드 3 )
adj = [[] for _ in range(10)] # 인접 리스트
def dfs(cur, par):
for nxt in adj[cur]:
if nxt == par:
continue
dfs(nxt, cur)
이진 트리의 순회
- 이진트리 : 각 노드의 자식이 최대 2개인 트리

| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| lc | - | 2 | 4 | 6 | 0 | 0 | 0 | 0 | 0 |
| rc | - | 3 | 5 | 7 | 0 | 8 | 0 | 0 | 0 |
| parent | - | 0 | 1 | 1 | 2 | 2 | 3 | 3 | 5 |
- 이진트리에 대해서는 따로 이름이 붙은 순회들이 있음
- 레벨 순회, 전위/중위/후위 순회
- 이진트리를 코드로 표현하는 방법 : 기존처럼 인접리스트같이 adj 를 만들어 하면, 왼쪽 자식과 오른쪽 자식을 구분할 수 없음
- 위 표에서 lc 는 left child, rc는 right child의 약자. 0은 해당 자리가 비어있음을 의미. 위 표와같이 배열로 표현할 수 있음
이진 트리 레벨 순회( Level-order Traversal)
- 이름 그대로 레벨. 즉, 높이 순으로 방문하는 순회
- 위 이진 트리 그림에서 $1 \rightarrow 2 \rightarrow 3 \rightarrow 4 \rightarrow 5 \rightarrow 6 \rightarrow 7 \rightarrow 8$ 순으로 방문하면 그게 레벨 순회
- 루트에서 bfs를 돌리면 레벨 순회가 됨. 단, lc, rc로 트리를 표현하고 있는 상황이므로 이에 맞는 bfs 코드를 짜주면 됨
from collections import deque
lc = [0, 2, 4, 6, 0, 0, 0, 0, 0] # 왼쪽 자식 배열
rc = [0, 3, 5, 7, 0, 8, 0, 0, 0] # 오른쪽 자식 배열
def bfs():
q = deque()
q.append(1) # 루트는 1번 노드
while q:
cur = q.popleft()
if lc[cur]: # lc[cur]이 0 이면 False, 0이 아니면 True
q.append(lc[cur])
if rc[cur]:
q.append(rc[cur])
이진 트리 전위 순회(Preorder Traversal) ($나 \rightarrow 왼 \rightarrow 오$)
- 현재 정점을 방문한다
- 왼쪽 서브 트리를 전위 순회한다
- 오른쪽 서브트리를 전위 순회한다
각 노드에 도착할 때마다 위 3 과정을 수행한다고 생각하면 편한 것 같습니다
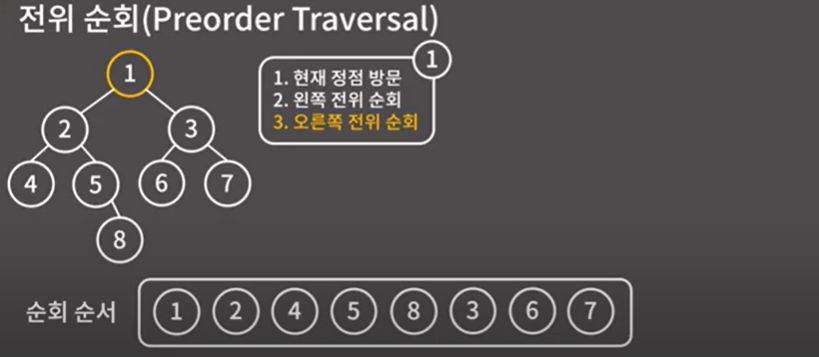
자세한 순회의 과정은 강의의 12분 정도를 확인하면 됩니다.
재귀로 구현할 때 감을 잡기 좋습니다.
- 전위 순회는 DFS와 방문 순서가 동일함.
lc = [0, 2, 4, 6, 0, 0, 0, 0, 0] # 왼쪽 자식
rc = [0, 3, 5, 7, 0, 8, 0, 0, 0] # 오른쪽 자식
def preorder(cur):
print(cur, end=' ')
if lc[cur] != 0:
preorder(lc[cur])
if rc[cur] != 0:
preorder(rc[cur])
이진 트리 중위 순회(Inorder Traversal) ($왼 \rightarrow 나 \rightarrow 오$)
- 왼쪽 서브 트리를 중위 순회한다
- 현재 정점을 방문한다
- 오른쪽 서브 트리를 중위 순회한다
각 노드에 도착할 때마다 위 3가지 과정을 수행한다고 생각하면 순회 순서를 도출하기 편한 것 같습니다
- 순회 순서 $4 \rightarrow 2 \rightarrow 5 \rightarrow 8 \rightarrow 1 \rightarrow 6 \rightarrow 3 \rightarrow 7$
# 왼쪽 자식과 오른쪽 자식 배열
lc = [0, 2, 4, 6, 0, 0, 0, 0, 0]
rc = [0, 3, 5, 7, 0, 8, 0, 0, 0]
def inorder(cur):
if lc[cur] != 0:
inorder(lc[cur])
print(cur, end=' ')
if rc[cur] != 0:
inorder(rc[cur])
이진 트리 후위 순회(Postorder Traversal) ($왼 \rightarrow 오 \rightarrow 나$)
- 왼쪽 서브 트리를 후위 순회 한다
- 오른쪽 서브 트리를 후위 순회 한다
- 현재 정점을 방문한다
각 노드에 도착할 때마다 위 3가지 과정을 수행한다고 생각하면 순회 순서를 도출하기 편한 것 같습니다
- 순회 순서 $4 \rightarrow 8 \rightarrow 5 \rightarrow 2 \rightarrow 6 \rightarrow 7 \rightarrow 3 \rightarrow 1$
# 왼쪽 자식, 오른쪽 자식 배열
lc = [0, 2, 4, 6, 0, 0, 0, 0, 0]
rc = [0, 3, 5, 7, 0, 8, 0, 0, 0]
def postorder(cur):
if lc[cur] != 0:
postorder(lc[cur])
if rc[cur] != 0:
postorder(rc[cur])
print(cur, end=' ')
서로 다른 트리여도 순회 결과가 일치할 수 있다
- 아래 두 트리의 경우 중위 순회 결과 $2\rightarrow 1 \rightarrow 3$으로 동일

연습 문제
나의 답
import sys
input = sys.stdin.readline
sys.setrecursionlimit(10**6)
node_num = int(input())
adj = [[] for _ in range(node_num + 1)]
# tree의 edge 수는 node 수 -1
for i in range(node_num-1):
u,v = map(int, input().split())
adj[u].append(v)
adj[v].append(u)
# bfs하는데 vis대신에 부모를 기록한 리스트 p
p = [0] * (node_num+1)
from collections import deque
q = deque()
q.append(1) # 1 이 root
while q:
curr = q.popleft()
# 트리 순회시에는 부모 노드를 스킵해야함
for next_node in adj[curr]:
if p[curr] == next_node:
continue
q.append(next_node)
p[next_node] = curr
for answer in p[2:]:
print(answer)
영상 답
import sys
sys.setrecursionlimit(10**6) # 재귀 깊이 제한 해제 (100,000개까지 가능)
n = int(sys.stdin.readline())
adj = [[] for _ in range(n + 1)]
p = [0] * (n + 1)
# 간선 입력 받기
for _ in range(n - 1):
u, v = map(int, sys.stdin.readline().split())
adj[u].append(v)
adj[v].append(u)
# DFS 함수
def dfs(cur):
for nxt in adj[cur]:
if p[cur] == nxt:
continue
p[nxt] = cur
dfs(nxt)
# 1번이 루트
dfs(1)
# 2번부터 출력
for i in range(2, n + 1):
print(p[i])
나의 답
import sys
input = sys.stdin.readline
node_num = int(input())
lc = [0]*(node_num+1) # 왼쪽 자식 노드
rc = [0]*(node_num+1) # 오른쪽 자식 노드
#ord('A') 는 65, ord('B') 는 66... ord('.') 는 46 임
criter = ord('A') - 1
for _ in range(node_num):
c,l,r = map(str, input().split())
c = ord(c) -criter
l = ord(l) -criter
r = ord(r) -criter
lc[c] = l
rc[c] = r # . 의 경우 음수로 기록됨
preorder = []
inorder = []
postorder = []
def order(start_node):
preorder.append(start_node)
if lc[start_node] > 0:
order(lc[start_node])
inorder.append(start_node)
if rc[start_node] >0 :
order(rc[start_node])
postorder.append(start_node)
order(1) # 루트는 A
preorder = [chr(i + criter) for i in preorder]
inorder = [chr(i + criter) for i in inorder]
postorder = [chr(i + criter) for i in postorder]
print(''.join(preorder))
print(''.join(inorder))
print(''.join(postorder))
영상 답
import sys
input = sys.stdin.readline
n = int(input())
lc = [0] * 30 # 왼쪽 자식
rc = [0] * 30 # 오른쪽 자식
# 'A' = 1, 'B' = 2, ..., '.' = 0 으로 처리
for _ in range(n):
c, l, r = input().split()
cur = ord(c) - ord('A') + 1
if l != '.':
lc[cur] = ord(l) - ord('A') + 1
if r != '.':
rc[cur] = ord(r) - ord('A') + 1
def preorder(cur):
print(chr(cur + ord('A') - 1), end='')
if lc[cur] != 0:
preorder(lc[cur])
if rc[cur] != 0:
preorder(rc[cur])
def inorder(cur):
if lc[cur] != 0:
inorder(lc[cur])
print(chr(cur + ord('A') - 1), end='')
if rc[cur] != 0:
inorder(rc[cur])
def postorder(cur):
if lc[cur] != 0:
postorder(lc[cur])
if rc[cur] != 0:
postorder(rc[cur])
print(chr(cur + ord('A') - 1), end='')
# 루트는 항상 'A' → 1
preorder(1)
print()
inorder(1)
print()
postorder(1)
print()반응형
'Algorithm > 정리' 카테고리의 다른 글
| [TIL] 250629 - 정렬 (0) | 2025.06.29 |
|---|---|
| [TIL] 250628 - 그리디 (Greedy) (0) | 2025.06.29 |
| [TIL] 250607 - 그래프 (0) | 2025.06.07 |
| [TIL] 250605 - 완전 탐색 가능 여부 판단 기준(시간 복잡도) (0) | 2025.06.05 |
| [TIL] 250531 - 이분탐색(Lower Bound / Upper Bound / Custom Bound) (0) | 2025.05.31 |
'Algorithm/정리' Related Articles
more
