
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- Deque
- explainable recommendation
- 우선순위 큐
- Recommendation
- isalpha()
- 정렬
- 코테
- find()
- 프로그래머스
- 백준
- isnumeric()
- 알고리즘
- Algorithm
- LSTM
- Knowledge graph
- 파이썬
- 추천시스템
- 그래프
- DP
- kg
- Stack
- 자료구조
- Dynamic Programming
- knowledge
- Python
- isalnum()
- isdigit()
- bfs
- 그래프 탐색
- 동적 프로그래밍
- Today
- Total
데린이 고인물되기
[KG_2019]KGAT: Knowledge Graph Attention Network for Recommendation 본문
[KG_2019]KGAT: Knowledge Graph Attention Network for Recommendation
데린이 성장 중 2024. 7. 24. 12:07https://taewan2002.medium.com/kgat-paper-review-457031b9fa28
KGAT paper review
KGAT는 Knowledge graph attention network으로 “지식 그래프”와 “어텐션”을 활용하는 추천 모델입니다. 이전의 FM, Wide&Deep 등 SL 방식의 모델들이 side-information을 잡으려고 했지만…
taewan2002.medium.com
https://process-mining.tistory.com/193
TransR knowledge graph embedding 설명 (TransR 설명)
TransR은 knowledge graph embedding 방법 중 하나로, projection matrix를 활용해서 head와 tail node embedding을 projection한 값 사이의 relation을 모델링하는 embedding 방법을 말한다. 이번 글에서는 RotatE, TransE에 이어,
process-mining.tistory.com
[논문리뷰] KGAT: Knowledge Graph Attention Network for Recommendation
Abstract
velog.io
https://summergurl.tistory.com/18
[RecSys] KGAT : Knowledge Graph Attention Network forRecommendation 논문 리뷰, 수식 설명
👩🏻💻 본 포스팅은 개인적 공부를 위해 논문 KGAT를 정리한 포스팅으로, 오류가 있을 수 있습니다. 이전에 포스팅했던 LightGCN은 GCN의 연장선으로, 사용자와 아이템 간의 연관성을 고려하는
summergurl.tistory.com
이번 논문 리뷰는 번역에 집중하기보다는 제 언어로 풀어 써보았습니다. 생략 및 오류 많을 수 있음 주의.
ABSTRACT
더 정확하고, 다양하며, 설명 가능한 추천을 제공하기 위해서는 user-item interaction 모델링을 넘어 side information을 고려하는 것이 필수적임.
ㆍ기존 방식의 한계 :
- FM(factorization machine)같은 기존 method들은 아이템 간의 관계나 interaction을 충분히 반영하지 못하는 문제가 있음.(user와 item간의 직접적인 관계는 고려하나, user와 user간의 유사성,item과 item간의 유사성을 기반으로 하는 간접적인 관계를 고려하지 않는 것 같음)
- FM은 SL(supervised learning)방식으로, 데이터에서 레이블(user의 item평가 같은거)을 이용함. 그리고 모델에 side information(사용자의 나이, 성별, 상품 카테고리 같은 것들)을 포함시켜 각 인스턴스를 더 잘 설명할 수 있도록 함. 이 과정에서 각 인스턴스(데이터 포인트)는 독립적으로 처리되고, 주어진 특성에 따라 인코딩됨. 각 특성과 레이블 간의 상호작용을 모델링해서 예측의 정확도를 높이려는 모델임.
- 그러나, 이런 전통적인 방식은(대표적으로 FM) user나 item간의 realtion나 네트워크 구조를 고려하지 않음. 예를 들어, 사용자가 비슷한 취향을 가지고 있다는 정보나, 두 상품이 서로 유사하다는 정보는 이런 모델에서는 직접적으로 모델링 되지 않음.
- 이렇게 되면 user나 item간의 관계를 무시하게 되어서 CF에서 중요한 신호를 녹여내지 못하는 한계가 있음.
- CF : 협엽 필터링으로, 다수의 사용자가 어떻게 상품을 평가하는지를 바탕으로 user간의 유사성이나 아이템간의 유사성을 찾아내는 기술.
⇒ 본 논문에서는, items와 그들의 속성을 연결하는 KG의 유용성을 탐구해서 이런 한계를 극복하고자 함. (user와 item간의 interaction들이 있을 떄 이들 각각을 독립적으로 보는 기존의 방법을 극복하고 네트워크 구조적인 측면에서 더 나은 학습을 할 수있도록 하기 위함)
- 우리는 KG와 user-item graph의 하이브리드 구조(CKG)에서, high-order relations는 성공적인 recommendation에 매우 필수적인 요소라고 주장함.
- high-order relations : 하나 또는 여러개의 연결된 속성으로 두 item을 연결하는 관계.1-hop이 아니라 여러 hop을 거쳐 연결된 관계 정도로 이해함.
- ∴ KG의 high-order 연결성을 end-to-end 방식으로 명시적으로 모델링하는 새로운 방법인 KGAT( Knowledge Graph Attention Network )를 제안함.
- KGAT
- 1) recursive embedding propagation
- node의 neighbors(users,items 또는 attributes일 수 있음)로부터 임베딩을 재귀적으로 전파하여 노드의 임베딩을 개선함.
더보기임베딩을 재귀적으로 전파하여 노드의 임베딩을 개선한다? : 노드(사용자, 아이템, 속성)의 임베딩을 주변 노드로부터 반복적으로 받아들이고 이를 통해 노드의 임베딩을 점차적으로 개선해 나간다는 의미
* 임베딩 : 노드의 특성을 수치 벡터로 표현한 것. 모델이 노드간의 유사성을 계산하고, 예측을 수행하는 데 사용됨.
* 재귀적 전파(recursive propagation) : 초기에는 각 노드이 임베딩을 설정하고, 각 노드는 자신의 이웃 노드들로부터 임베딩 정보를 받아옴. 받아온 이웃 노드의 임베딩 정보를 바탕으로 자신의 임베딩을 업데이트함. 이 과정을 여러번 반복(재귀적으로)하여 임베딩을 점차적으로 개선.
* 임베딩 개선 : 재귀전 전파 과정을 통해 노드가 주변 이웃들의 정보를 반영해 자신의 임베딩을 개선함. 예를 들어, user의 임베딩은 그 user가 좋아하는 아이템들(이웃 노드)의 임베딩을 반영하여 업데이트되고, 아이템 임베딩은 그 아이템을 좋아하는 user들의 임베딩을 반영하여 업데이트 됨
- node의 neighbors(users,items 또는 attributes일 수 있음)로부터 임베딩을 재귀적으로 전파하여 노드의 임베딩을 개선함.
- 2) attention-based aggregation
- neighbors의 중요성을 구별하기 위해 attention mechanism 사용.
- node propagation 과정에서 중요한 노드에 가중치를 주기위해 attention을 적용함.
- 1) recursive embedding propagation
- KGAT는 기존 CKG 기반 추천 method보다 좋음.
- 기존 KG 기반 추천 방법 :
- path- based methods :경로를 추출해 high-order relations를 활용
- regularization methods : 암시적으로 모델링.
- 기존 KG 기반 추천 방법 :
- 3 개의 public benchmarks에서의 실험 결과, KGAT는 Neural FM과 RippleNet같은 state-of-the-art methods보다 상당히 우수한 성능을 보임. 추가 연구에서는 high-order relation 모델링을 위한 embedding propagation의 효능과 attention mechanism이 가지고 오는 해석 가능성의 이점을 확인함.
1. Introduction
- user preference를 예측하기 위해 대부분의 연구는 CF를 사용함.
- CF methods는 side information(e.g., item attributes, user profiles, and contexts)을 모델링할 수 없음.
-> users와 items의 interactions이 적은 sparse situations에서는 성능이 저하됨.
- CF methods는 side information(e.g., item attributes, user profiles, and contexts)을 모델링할 수 없음.
- side information을 일반적인 feature vector로 변환한 다음, user ID와 item ID와 통합해서 supervised learning(SL) model에 입력해 score을 예측함.(=> side information도 모델링할 수 있도록)
- 대표적인 모델 : factorization machine (FM) [23], NFM (neural FM) [11], Wide&Deep [7], and xDeepFM [18], etc.
- -> 각 interaction을 독립적인 데이터 instance로 모델링해서 그들간의 relations을 고려하지 않음.
- -> users의 collective behaviors로부터 attribute-based collaborative signal을 추출하기 어려움.
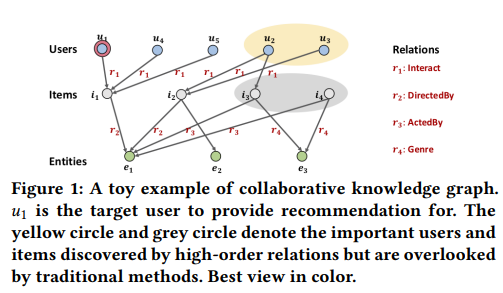
Figure 1을 보면, user \(u_1\)과 movie \(i_1\)사이에 interaction이 있고, \(i_1\)은 사람 \(e_1\)에 의해 directed by(감독) 되었음.
- CF methods는 \(i_1\)을 also watched한 similar users인 \(u_4\)와 \(u_5\)의 history에 중점을 둠.(유사한 사용자는 아이템에 대한 유사한 선호도를 나타냄. CF는 \(u_4\)나 \(u_5\)가 \(r_1\)으로 채택한 다른 영화가 있으면 그 영화를 \(u_1\)에게 추천할거임. )
- SL methods는 attribute(속성) \(e_1\)을 가진 similar items \(i_2\)에 중점을 둠.(CF와 달리 SL은 속성 기반 연결성에 초점을 맞추어 user가 유사한 attribute을 공유하는 아이템을 채택할 가능성이 있다고 가정함.즉, \(u_1\) 이 이전에 좋아한 \(i_1\) 과 같은 감독 \(e_1\) 을 가진 \(i_2\)를 채택할 것임 . 하지만 SL은 인스턴스 간의 관련성을 드러내지는 못해서 \(e_1\)이 director와 actor filed를 연결하는 다리역할을 함에도 그걸 파악하지 못함(\(e_1\)과 \(r_3\)로 연결된 아이템을 추천하지 못함))
- => 이 두가지 정보는 recommendation에 상호 보완적일 뿐만 아니라, target user와 item간의 high-order relationship을 형성함.
그러나 기존의 methods는 이를 통합하지 못하고 high-order connectivity를 고려할 수 없음
(e.g., \(i_1\)과 동일하게 \(e_1\)에 의해 감독( directed by , \(r_2\))된 다른 영화를 본 노란색 원 안의 users나
\(e_1\)과 다른 공통된 relations(\(r_3\))를 공유하는, 회색 원 안의 items 같은 high-order relationship을 고려할 수 없음)더보기쉽게 생각해보면, 기존의 CF방식은 \(i_1\)을 also watched한 similar users인 \(u_4\)와 \(u_5\)가 소비한 items를 추천한다거나, 기존의 SL 방식은 attribute(속성) \(e_1\)을 가진 similar items \(i_2\) (realtion도 \(i_1\)과 \(r_2\)로 동일한듯) 정도만 추천할 수 있음. 즉, high-order relationship 고려 불가능. 이런 의미인듯 - 우리는 feature-based SL models의 이런 한계를 극복하기 위해 CKG( collaborative knowledge graph )를 고려해 예측 모델 구성함.
- CKG : hybrid structure of knowledge graph and user-item graph. (-> item side information 그래프도 함께 고려할 수 있는듯)
- CKG에서 high-order relations를 충분히 활용하면 성공적인 recommendation이 가능.(노란 원과 회색 원)
- CKG에서 high-order information를 활용하기 위한 challenge
- 1) high-order relations에 있는 node는 차수가 증가함에 따라사이즈가 급격히 증가해 모델에 부담을 크게 줌
- 2) high-order ralations는 예측에 동일하게 기여하지 않기 떄문에 model이 신중하게 가중치(또는 선택)해야함.
- recommendation에서 CKG 구조의 기존의 접근법으로 크게 2가지 방식이 존재
- 1. path-based methods
- high-order information을 가지고 있는 paths를 추출하고 이를 predictive model에 입력함.
두 nodes 간의 많은 paths를 처리하기 위해...
주요 paths를 선택하기 위해 path selection algorithm을 적용하거나,
meta-path patterns를 정의해서 paths를 제한해주는 방식도 사용함. - 이런 tow-stage방식(path select -> 학습)의 문제점 :
- path selection이 최종 성능에 큰 영향을 미치는데, 이게 추천 목표에 최적화 되어 있지 않음.
- 효과적인 meta-paths를 정의하려면 도메인 지식이 필요하며, 다양한 type의 entity와 relation이 있는 복잡한 KG의 경우, model fidelity를 유지하기 위해 많은 meta-paths를 정의해야 해서 노동력이 많이 필요함.
- high-order information을 가지고 있는 paths를 추출하고 이를 predictive model에 입력함.
- 2. regularization-based methods
- KG구조를 캡처하는 추가적인 loss terms를 고안해 추천 모델 학습을 regularize함.
- recommendation과 KG completion 이렇게 2가지 task를 수행. 이 방식의 문제점은 KG completion도 학습의 과정에서 만들어지다보니, high-order relation을 모델에 explict한 방식이 아니라 implicit하게 줌. (KG completion이 학습과정에서 아마 optimal할 것이라는 전제를 가지고 recommendation이 이뤄지니까 high-order relation을 제대로 capture한다고 보기 어렵다) 그리고 implicit 인코딩 때문에, 모델의 결과를 명확하게 해석하기 어려움.
- KG구조를 캡처하는 추가적인 loss terms를 고안해 추천 모델 학습을 regularize함.
- 1. path-based methods
따라서 논문에서 제시된 KGAT( Knowledge Graph Attention Network )는
Efficient (path 방식의 labor-intensive하다는 문제점 극복) +
Explicit (Regularization 방식의 implicit하다는 문제점 극복) +
End-To-End (path 방식의 two-stage 문제점 극복) 형태로 고안되었다.
- KGAT는 위에서 설명한 CKG에서 high-order information를 활용하기 위한 challenge 를 다음과 같이 극복함.
- 1) high-order relations에 있는 node는 차수가 증가함에 따라사이즈가 급격히 증가해 모델에 부담을 크게 줌.
- recursive embedding propagation을 이용해 해결 :
- 각 노드의 임베딩을 그 노드의 neighbor 노드의 임베딩을 기반으로 업데이트 해줌. 이 과정을 반복하면, high-order connectivities를 linear time complexity하게 파악할 수 있음.
-
더보기
chat gpt의 말씀
Recursive Embedding Propagation의 효율성**재귀적 임베딩 전파(Recursive Embedding Propagation)**는 KGAT가 고차(high-order) 관계를 효율적으로 모델링할 수 있게 해주는 핵심 메커니즘입니다. 이 방식이 효율적인 이유를 단계별로 설명해 보겠습니다.
재귀적 임베딩 전파의 과정
- 기본 임베딩 생성:
- 초기 단계에서 각 노드는 자체적으로 고유한 임베딩을 가집니다. 예를 들어, 사용자와 아이템 각각에 대해 초기 임베딩 벡터를 할당합니다.
- 이웃 노드 임베딩 수집:
- 각 노드는 자신과 직접 연결된 이웃 노드(1-hop 이웃)의 임베딩을 수집합니다.
- 이를 통해 1차 관계 정보를 수집하게 됩니다.
- 임베딩 업데이트:
- 수집된 이웃 노드의 임베딩을 바탕으로 자신의 임베딩을 업데이트합니다.
- 이 과정이 한 번 완료되면, 각 노드는 자신과 1-hop 이웃의 정보를 반영한 임베딩을 가지게 됩니다.
- 재귀적 전파:
- 업데이트된 임베딩을 다시 사용하여 이웃 노드의 임베딩을 재귀적으로 수집하고, 자신의 임베딩을 다시 업데이트합니다.
- 이 과정을 여러 번 반복함으로써, 2-hop, 3-hop 등 더 높은 차수의 관계 정보를 점진적으로 반영하게 됩니다.
효율성의 이유
- 선형 시간 복잡도:
- 재귀적 임베딩 전파는 각 단계에서 직접 연결된 이웃의 임베딩만 수집하고 업데이트하기 때문에, 각 노드의 업데이트는 선형 시간 복잡도에서 수행됩니다. 이로써 모델은 계산 과부하를 줄이면서 고차 관계를 반영할 수 있습니다.
- 점진적 정보 통합:
- 정보가 단계별로 점진적으로 통합되기 때문에, 노드 간의 복잡한 고차 관계를 효율적으로 캡처할 수 있습니다. 초기 임베딩에서 시작해 각 단계에서 이웃 노드의 정보를 통합함으로써, 모델은 자연스럽게 고차 관계를 반영하게 됩니다.
- 효율적인 메모리 사용:
- 재귀적 전파는 각 단계에서 필요한 이웃 노드의 임베딩만을 메모리에 유지하기 때문에, 대규모 그래프에서도 효율적인 메모리 사용이 가능합니다. 이는 특히 대규모 지식 그래프에서 중요한 장점입니다.
- 기본 임베딩 생성:
- recursive embedding propagation을 이용해 해결 :
- 2) high-order ralations는 예측에 동일하게 기여하지 않기 떄문에 model이 신중하게 가중치(또는 선택)해야함.
- attention-based aggregation을 이용해 해결 :
- propagation(전파) 중 각 neighbor의 가중치를 학습하기 위해 neural attention mechanism을 사용하는 attention-based aggregation을 사용함.
- attention-based aggregation을 이용해 해결 :
- 1) high-order relations에 있는 node는 차수가 증가함에 따라사이즈가 급격히 증가해 모델에 부담을 크게 줌.
2. Task Formulation
User-Item Bipartite Graph:
우리는 interaction data를 user-item bipartite graph \(\mathcal{G}_1\)로 표현. 이 그래프는 \(\{(u,y_{u i},i)|u\in\mathcal{U},i\in\mathcal{I})\}\) 로 정의됨.
여기서 \(\mathcal{U}\)와 \(\mathcal{I}\)는 각각 user와 item 집합을 의미. link \(y_{ui} = 1\)은 user \(u\)와 item \(i\) 사이에 관찰된 interaction이 있음을 나타내고, \(y_{ui} = 0\)은 그렇지 않음을 나타냄.
Knowledge Graph:
interactions 외에도 아이템에 대한 side informations( e.g., item attributes and external knowledge )이 있음.일반적으로 이런 auxiliary data는 아이템을 설명하기 위해 real-world의 엔티티와 그들간의 relation으로 구성됨.우리는 side information을 subject-property-object 이렇게 triplet facts로 구성된 directed graph인 knowledge graph \(mathcal{G}_2\)의 형태로 구성함.\(\{(h,r,t)|h,t\in{\mathcal{E}},r\in{\mathcal{R}}\}\) 와 같이 표현함.여기서 각 triplet은 head entity \(h\)에서 tail entity \(t\)로의 relation \(r\)이 있음을 묘사한거임.\(\mathcal{R}\)은 canonical direction(표준방향)과 inverse direction(역방향) 관계를 모두 포함함.
게다가, 우리는 item-entity alignments 집합 \({\mathcal{A}}\,=\,\{(i,e)|i\,\in\mathcal{I},e\,\in\,{\mathcal{E}}\}\)를 설정함. 여기서, \((i,e)\)는 아이템 \(i\)가 KG의 엔티티 \(e\)와 정력될 수 있음을 나타냄.
Collaborative Knowledge Graph
user behaviors과 item knowledge을 통합한 relational graph로 인코딩하는 CKG 개념을 정의함.
1. 우선 각 user behavior을 triplet \((user, interact, i)\)로 나타냄.(\(\mathcal{G}\)의 \(y_{ui}=1\)이 여기서는 \(interact\))
2. 그런 다음 user-entity alignment set을 기반으로 user-item Bipartite graph를 KG와 통합된 그래프 CKG를 만듦. (\(\mathcal{G}\)) : $${\mathcal{G}}=\{(h,r,t)|h,t\in{\mathcal{E}}^{\prime},r\in{\mathcal{R}}^{\prime}\}$$
\({\mathrm{where~}}{\mathcal{E}}^{\prime}={\mathcal{E}}\cup{\mathcal{U}}{\mathrm{~and~}}{\mathcal{R}}^{\prime}={\mathcal{R}}\cup\{I n t e r a c t\}\)
=> 이렇게 해서 user, item, 지식 그래프 개체를 모두 포함하는 통합된 그래프 구조를 만들 수 있음
Task Description :
- input : user-item bipartite graph \(\mathcal{G}_1\) and knowledge graph \(mathcal{G}_2\)를 포함하는 CKG \(mathcal{G}\)
- output : user \(u\)가 item \(i\)를 채택할 확률 \({\hat{y}}_{u i}\)를 예측하는 예측 함
High-Order Connectivity
고품질 추천을 위해서는 high-order connectivity를 활용하는 것이 중요함.
- 우리는 노드 간의 L-order connectivity을 multi-hop relation 경로로 정의함. : \(e_{0}\stackrel{r_{1}}{\longrightarrow}e_{1}\stackrel{r_{2}}{\longrightarrow}\cdot\cdot\cdot\cdot\stackrel{r_{L}}{\longrightarrow}e_{L},\mathrm{where}\;e_{l}\in\textstyle{E^{\prime}}\mathrm{and}\;r_{l}\in\mathcal{R^{\prime}}\)
3. METHODOLOGY
여기서는 high-order relation을 end-to-end 방식으로 활용하는 KGAT모델에 대한 내용.
Figure 2는 모델 프레임워크를 보여줌. 3가지 주요 구성요소로 구성됨을 알 수 있음.
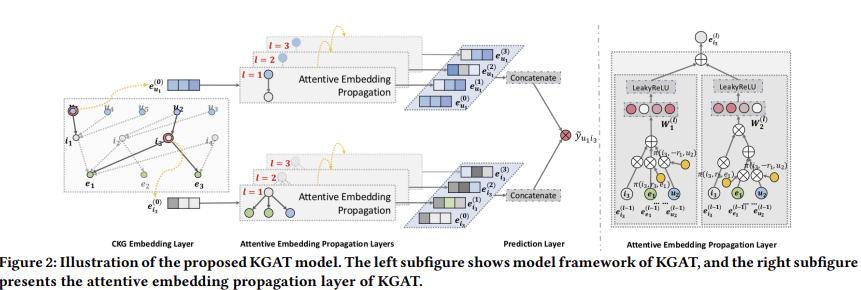
- 1) CKG embedding layer
- CKG 구조를 보존하면서 각 노드를 벡터로 parameter화 하여 CKG구조를
- 2) Attention Embedding Propagation Layers
- neighbor 노드에서 임베딩을 재귀적으로 전파해 노드의 표현을 갱신하고, propagation 중 각 이웃의 중요성을 학습하기 위해 knowledge-aware attention mechanism을 사용함.
- 3) Prediction Layer
- 모든 propagation layer에서 온 user와 item의 표현을 집계하고 predicted matching score을 output으로 내놓음
3.1 Embedding Layer
- KG 임베딩 : 그래프 구조를 유지하면서 엔티티와 relation을 벡터 표현으로 parameterize해주는 방법.
- 우리는 CKG에 널리 사용되는 TransR이라는 방식을 채택함.TransR을 이용한 Embedding 수행.
- TransR : entity와 relation은 서로 다른 성질을 가지고 있어서 둘을 서로 다른 공간에 정의.head와 tail의 임베딩은 엔티티 space에 정의하고 realtion 임베딩은 relation space에 정의한 뒤, head와 tail 임베딩을 relation space로 차원을 변환해주고 이 둘 사이의 relation을 찾는 것을 목적으로 방식. 차원을 바꿀때 곱해주는게 여기서는 \(W_r\)로 표현한 듯.
- 구체적으로 보면, 그래프에 triplet \((h,r,t)\)가 있을 때, \(\mathbf{e}_{h}^{r}+\mathbf{e}_{r}\approx\mathbf{e}_{t}^{r}\)를 최적화하여 각 엔티티와 relation을 임베딩함.
- 여기서, \(\mathrm{e}_{h},\mathrm{e}_{t}\in\mathbb{R}^{d}{~and~}\mathrm{e}_{r}\in\mathbb{R}^{k}\)는 각각 h,t 및 r의 임베딩.
- \(\mathbf{e}_{h}^{r},\mathbf{e}_{t}^{r}\)은 \(r\) space에서 \(\mathbf{e}_{h}{\mathrm{~and~}}\mathbf{e}_{t}\)의 투영된 표현. 그러니까 그냥 각각 \(\mathbf{W}_{r}\mathbf{e}_{h}\),\(\mathbf{W}_{r}\mathbf{e}_{t}\)의미하는 듯.
- 따라서, 주어진 triplet \((h,r,t)\)에 대해, plausiblity score(or energy score)은 식 (1) 과 같음.
- $$g(h,r,t)=\|{\bf W}_{r}{\bf e}_{h}+{\bf e}_{r}-{\bf W}_{r}{\bf e}_{t}\|_{2}^{2}\,,\qquad\qquad\qquad(1)$$
- r's space로 투영하는거니까 r읜 r's space에서의 임베딩 그대로. 즉, \(W_r\)안 곱함
- 여기서 \(W_{r}\in R^{k\times d}\)는 relation \(r\)의 transformation matrix.엔티티를 d-dimension entity space에서 k-dimension relation space로 project해줌.
- 식(1)의 값이 작을수록, triplet이 참일 가능성이 높은거고, 값이 클수록 참일 가능성이 낮은거임.
- TransR의 training은 valid한 triplet과 broken triplet(유효하지 않은 triplet. 그냥 entity하나 negative sampling한 거 같음)간의 상대적인 order을 고려함.즉, 이 둘 사이의 차이가 커지는 방향으로 학습하도록 장려함. 이때 pariwise ranking loss인 식(2)를 사용.
- $$\mathcal{L}_{\mathrm{KG}}=\sum_{(h,r,t,t^{\prime})\in\mathcal{T}}-\ln\sigma\Bigl(g(h,r,t^{\prime})-g(h,r,t)\Bigr),\qquad\qquad(2)$$
- 여기서 \(g(h,r,t^{\prime})-g(h,r,t)\)가 커질수록, loss 전체적인 식 관점에서는 loss가 줄어들도록 식 설계를 해서 TransR이 \(g(h,r,t^{\prime})-g(h,r,t)\)의 간격을 벌리도록 학습을 하게 하는 듯.
- \( \mathcal{T}=\{(h,r,t,t^{\prime})|(h,r,t)\in\mathcal{G},(h,r,t^{\prime})\notin\mathcal{G}\} \),
즉 \((h,r,t^{\prime})\)가 broken triplet. valid triplet에서 무작위로 하나의 엔티티를 교체해 생성한 triplet - \({\sigma}(\cdot)\)는 sigmoid function
- $$\mathcal{L}_{\mathrm{KG}}=\sum_{(h,r,t,t^{\prime})\in\mathcal{T}}-\ln\sigma\Bigl(g(h,r,t^{\prime})-g(h,r,t)\Bigr),\qquad\qquad(2)$$
Embedding layer는 entities와 relations를 모델링하며 regularizer 로 작동하여 representations에 직접적인 connections을 주입해 모델의 representation ability를 증가시킴(section 4.4.3에서 실험함)
3. 2 Attentive Embedding Propagation Layers
embedding layer 다음으로는 graph convolution network의 architecture을 기반으로 하여 high-order connectivity를 따라 embedding 을 recursively하게 전파(propagate)함. 게다가, graph attention network의 아이디어를 활용해 attentive weights을 생성함. attentive weights는 cascaded propagations에서 connectivity의 중요성을 드러내기 위함임.
중요한 관계에는 더 큰 값을 부여하기 위해 총 3개의 구성요소로 구성됨.( Information Propagation , knowledge-aware attention , information aggregation )
Information Propagation :
- 하나의 entity는 여러 triplets에 관여할 수 있으며, 이는 2개의 triplets을 연결하고 정보를 전파하는 다리 역할을 함.
- \(e_{1}\ \ \xrightarrow{\tau_{2}}\ \ \ i_{2}\ \ \xrightarrow{-r_{1}}\ \ \ u_{2}\)와 \(e_{2}\ {\overset{r_{3}}{\longrightarrow}}\ i_{2}\ {\overset{-r_{1}}{\longrightarrow}}\ u_{2}\)를 예로 들면, item \(i_2\)는 attributes \(e_1\)과 \(e_2\)를 input으로 받아 자신의 feature를 enrich하게 하고, 그런 다음 user \(u_2\)의 preference에 기여함. 이는 \(e_1\)에서 \(u_2\)로 information을 propagation하여 시뮬레이션할 수 있음. 우리는 이 직관을 기반으로 entity와 그 neighbors간의 information propagation을 수행함.
- 여기서 가장 중요한 키워드는 "ego-network"인데 , ego-network는 특정 엔티티와 그 엔티티와 직접 연결된 이웃 엔티티들로 구성된 네트워크임. 아래 식 특정 head의 neighbor로부터 propagate되는 모든 embedding을 표현한 수식임.
- $$\begin{array}{c c}{{\mathbf{e}_{N_{h}}=\displaystyle\sum_{(h,\,r,\,t)\in N_{h}}\pi(h,\,r,\,t)\mathbf{e}_{\,\ell},\qquad\qquad\qquad\qquad\qquad(3)}}\end{array}$$
- \(\mathcal{N}_{h}\) : h가 head entity인 triplet 집합. \(N_{h}\,=\,\{(h,r,t)|(h,r,t)\in{\mathcal{G}}\}\)
- \(\pi(h,r,t)\) : edge \((h,r,t)\)에서, 관계 r에 따라 t에서 h로 전파되는 정보의 양을 나타냄.즉, 각 이웃 엔티티로부터 전파되는 정보의 중요도를 조정하는 가중치. attention score임. relation r의 공간에서 h와 t사이의 거리를 기반으로 계산됨. 가까운 이웃 엔티티일수록 더 높은 점수가 부여됨.
- (이 값에 head의 neighbor 엔티티와 그 엔티티의 중요도에 대한 정보를 담고 있으므로, 이 값과 기존의 head 임베딩 값을 이용해 head 임베딩을 업데이트하고(이게 뒤에 나오는 information aggregation과정인 듯), 또 레이어를 거치면서 같은 작업을 반복해서 head 임베딩을 업데이트하고, 이 과정을 반복하는듯. 이렇게 되면 head 임베딩이 레이어를 거칠수록 이웃 노드들의 중요도까지 반영한 값으로 업데이트 될것. 이 과정이 결국 recursive 하다는 것 같음. 초기에 임베딩 값은 embedding layer을 거친 TransR을 이용해 학습한 임베딩인거고, 여기에서 주변 노드 중요도에 대한 정보를 포함하도록 임베딩을 또 업데이트하는거고)
knowledge-aware attention :
relational attention mechanism을 통해 \(\pi(h,r,t)\)을 구현함. :
$$\pi(h,r,t)=\big({\bf W}_{r}{\bf e}_{t}\big)^{\top}\mathrm{tanh}\Big(({\bf W}_{r}{\bf e}_{h}+{\bf e}_{r})\Big),\qquad\qquad(4)$$
- r's space에서 \(e_h\)와 \(e_t\)사이의 거리에 따라 attention score가 바뀌도록 식이 구성되어 있음. -> 더 가까운 엔티티에 대해 더 많은 정보전파함.(attention score가 커지니)
- 비선형 활성화 함수로 tanh를 선택해서 어텐션 가중치 범위를 제한하고, 비 선형성을 도입해 모델의 표현력을 향상시킴
- 단순화를 위해 이러한 표현에서 내적만을 사용하며, attention 모듈의 추가 탐색은 향후 작업으로 남겨뒀다고 함.
이후 softmax 함수를 채택해 h와 연결된 모든 triplet에 대해 coefficient를 normalize함.
$$\pi(h,r,t)={\frac{\exp(\pi(h,r,t))}{\sum_{(h,r^{\prime},t^{\prime})\in N_{h}}\exp(\pi(h,r^{\prime},t^{\prime}))}}.\qquad\qquad(5)$$
- 결과적으로 최종 attention score는 collaborative score를 포착하기 위해 더 많은 attention을 기울여야 하는 이웃 노드를 suggest할 수 있음. forward propagation을 할 때, attention flow는 집중할 데이터 부분을 suggest하며, 이걸 recommendation의 explanations으로 처리할 수 있음.
\(\pi(h,r,t)\)를 저렇게 설정함으로써, 모델이 그래프의 근접 구조를 활용할 뿐만 아니라 neighbors의 중요도를 지정할 수 있음. 또한, graph attention network가 노드 representations만을 input으로 사용하는 것과 달리, 우리는 \(e_h\)와 \(e_i\)사이의 관계 \(e_r\)을 모델링하여 propagation 중 더 많은 정보를 인코딩함.
information aggregation :
최종 단계는 entity representation \(e_h\)와 ego-network representation \({e}_{\mathcal{N}_{h}}\)를 새 엔티티 \(h\)의 representation으로 aggregation하는 것임 : \(e_{h}^{(1)}=f(e_{h},e_{\mathcal{N}_h})\)
다음 3가지 유형의 aggregators를 사용해 \(f(\cdot)\) 구현 했는데 결론적으로 \(f_{\mathrm{Bi-Interaction}}\)의 성능이 가장 잘 나왔음.
- GCN Aggregator : 두개의 representation을 합산하고 비선형 변환을 적용함.
- $$f_{\mathrm{GCN}}=\mathrm{LeakyReLU}\Bigl({\bf W}(\mathrm{e}_{h}+\mathrm{e}_{N_{h}})\Bigr),\qquad\qquad\qquad(6)$$
- 활성화 함수는 LeakyReLU를 설정함. \({W}\ \in\ {\mathbb R}^{d^{\prime}\times d}\)은 유용한 information을 propagation하기 위해 trainable한 weight 행렬임. \(d^{\prime}\)은 transformation size.
- $$f_{\mathrm{GCN}}=\mathrm{LeakyReLU}\Bigl({\bf W}(\mathrm{e}_{h}+\mathrm{e}_{N_{h}})\Bigr),\qquad\qquad\qquad(6)$$
- GraphSage Aggregator : 2개의 representation을 concatenate한 다음 비선형 변환을 수행함.
- $$f_{\mathrm{GraphSage}}=\mathrm{LeakyReLU}\bigg({\bf W}(\mathrm{{e}}_{h}||\mathrm{{e}}_{N_{h}})\bigg),\qquad\qquad(7)$$
- || : concatenation operation
- $$f_{\mathrm{GraphSage}}=\mathrm{LeakyReLU}\bigg({\bf W}(\mathrm{{e}}_{h}||\mathrm{{e}}_{N_{h}})\bigg),\qquad\qquad(7)$$
- Bi-Interaction Aggregator : \(e_h\)와 \(e_{\mathcal{N}_h}\) 사이의 2가지 종류의 feature interactions를 고려하기 위해 우리가 설계함.
- $$\begin{array}{c}{{f_{\mathrm{Bi-Interaction}}=\mathrm{LeakyReLU}(W_{1}(\mathbf{e}_{h}+\mathbf{e}_{N_{h}}))+}}\\ {{}}&{{}}\\ {{\mathrm{LeakyReLU}(W_{2}(\mathbf{e}_{h}\odot\mathbf{e}_{N_{h}})),}}\end{array}\qquad\qquad(8)$$
- \(\mathrm{W}_{1},\mathrm{W}_{2}\ \ \in\ \mathbb{R}^{{d^\prime}\times d}\)는 trainable한 가중치 행렬.
- \(\odot\) : element-wise product
- 단순히 벡터 합을 쓰거나 이어붙이는걸 쓰는 것보다 해당 방식은 두 벡터의 합과 요소별 곱을 둘 다 해서 두 벡터간의 상호작용을 더 잘 포착할 수 있는듯. 이렇게 하면 유사한 엔티티 간의 관계를 강조한다고 함. 그래서 유사한 엔티티에서 더 많은 정보가 전파될 수 있다고 함.
- $$\begin{array}{c}{{f_{\mathrm{Bi-Interaction}}=\mathrm{LeakyReLU}(W_{1}(\mathbf{e}_{h}+\mathbf{e}_{N_{h}}))+}}\\ {{}}&{{}}\\ {{\mathrm{LeakyReLU}(W_{2}(\mathbf{e}_{h}\odot\mathbf{e}_{N_{h}})),}}\end{array}\qquad\qquad(8)$$
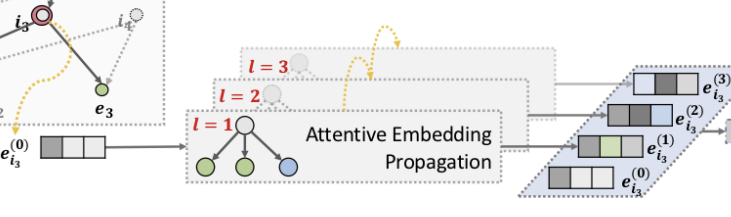
High-order Propagation :
위에서는 single layer에 대한 설명이었지만, 더 많은 propagation layer들을 쌓아 high-order connectivity information을 탐색하고, higher-hop neighbors로부터 전파된 information을 수집할 수 있음.
\(l\)-th steps에서 엔티티의 representation을 재귀적으로(recursively) 다음과 같이 공식화 함.:
$$\begin{array}{c c}{{\mathrm{e}_{h}^{(l)}=f\Big(\mathrm{e}_{h}^{(l-1)},\mathrm{e}_{N_{h}}^{(l-1)}\Big),\qquad\qquad\qquad\qquad\qquad\quad\quad(9)}}\end{array}\quad\quad\quad\quad\quad\quad\quad\quad(9)$$
여기서 엔티티 \(h\)에 대해 \(l-ego\) network 내에서 전파된 정보는 다음과 같이 정의됨.:
$$\mathrm{e}_{N_{h}}^{(l-1)}=\sum_{(h,r,t)\in N_{h}}\pi(h,r,t)\mathrm{e}_{t}^{(l-1)},\qquad\qquad\qquad(10)$$
3.2 Model Prediction
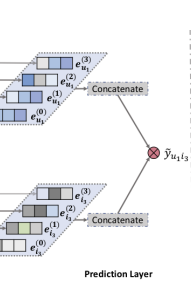
L layers를 거치고 나면, multiple representations를 얻게 됨
- \(u\),\(\{\mathbf{e}_{u}^{(1)},\cdot\cdot\cdot,\mathbf{e}_{u}^{(L)}\}\)
- \(i\), \(\{\mathbf{e}_{i}^{(1)},\cdot\cdot\cdot,\mathbf{e}_{i}^{(L)}\}\)
=> 서로 다른 레이어의 출력은 서로 다른 orders의 연결성 정보를 강조함. 따라서 우리는 각 step에서 나온 representations을 single vector로 concatenate하는 layer-aggregation mechanism을 채택함.:
$$\mathbf{e}_{u}^{\ast}=\mathbf{e}_{u}^{(0)}||\cdot\cdot\cdot||\mathbf{e}_{u}^{(L)},\quad\mathbf{e}_{i}^{\ast}=\mathbf{e}_{i}^{(0)}||\cdot\cdot\cdot||\mathbf{e}_{i}^{(L)},\qquad\qquad(11)$$
마지막으로, user와 item representations의 내적을 수행해 matching score를 예측함.:
$$\hat{y}(u,i)=\mathrm{{e}}_{u}^{*\top}\mathrm{{e}}_{i}^{*}\,.\qquad\qquad\qquad\qquad\qquad\qquad(12)$$
3.4 Optimization
KGAT에서는 다음과 같이 KG loss와 CF loss를 별도로 정의한 후 합쳐서 최종 loss function을 구성함.
$$\mathcal{L}_{\mathrm{KGAT}}=\mathcal{L}_{\mathrm{KG}}+\mathcal{L}_{\mathrm{CF}}+\lambda\left\|\Theta\right\|_{2}^{2},\qquad\qquad\qquad(14)$$
- \( \mathcal{L}_{\mathrm{KG}} \)는 3.1 embedding layer에서 도출된 loss를 의미. (embedding loss)
$$\mathcal{L}_{\mathrm{KG}}=\sum_{(h,r,t,t^{\prime})\in\mathcal{T}}-\ln\sigma\Bigl(g(h,r,t^{\prime})-g(h,r,t)\Bigr),\qquad\qquad(2)$$
- \( \mathcal{L}_{\mathrm{CF}} \)는 BPR loss(pairwise형태로 제시되는 bayes rule기반의 loss)를 기반으로 다음과 같이 정의(prediction loss). 아이템 i와 j 사이의 거리가 멀아지도록 함.
$$\mathcal{L}_{\mathrm{CF}}=\sum_{(u,i,j)\in O}-\ln\sigma\Bigl(\hat{y}(u,i)-\hat{y}(u,j)\Bigr)\qquad\qquad\qquad(13)$$
- : observed된 interaction(더 많은 user preference를 나타냄)가 unobserved interaction보다 prediction value가 크다는 가정하에 만들어짐.
- \({\cal O}=\{(u,i,j)|(u,i)\in R^{+},(u,j)\in R^{-}\}\)는 training set을 나타냄, \(\textstyle{\mathcal{R}}^{+}\) 는 observed(positive) interaction set을 나타내며, \(\textstyle{\mathcal{R}}^{-}\)는 생플링된 unobserved(negative) interaction 집합. σ(·) 는 sigmoid function
$$\mathcal{L}_{\mathrm{KGAT}}=\mathcal{L}_{\mathrm{KG}}+\mathcal{L}_{\mathrm{CF}}+\lambda\left\|\Theta\right\|_{2}^{2},\qquad\qquad\qquad(14)$$
- 위 식에서 \(\lambda\left\|\Theta\right\|_{2}^{2}\)
- \(\Theta=\{{\bf E},{\bf W}_{r},\forall l\in{\mathcal R},{\bf W}_{1}^{(l)},{\bf W}_{2}^{(l)},\forall l\in\{1,\cdots,L\}\}\)은 모델 parameter set.
- \( \bf E \)는 모든 entity 및 relation에 대한 embedding table.
- L2 정규화 항임(필요없는 파라미터를 0으로 가게 하는게 L1이고 L2는 0에 가깝게). 과적합 방지를 위해 넣음.
- \(\Theta=\{{\bf E},{\bf W}_{r},\forall l\in{\mathcal R},{\bf W}_{1}^{(l)},{\bf W}_{2}^{(l)},\forall l\in\{1,\cdots,L\}\}\)은 모델 parameter set.
3.4.1 Training : embedding loss( \( \mathcal{L}_{\mathrm{KG}} \) )와 prediction loss( \( \mathcal{L}_{\mathrm{CF}} \) )을 번갈아 가면서 최적화. embedding loss 와 prediction loss를 최적화 할 때 mini-batch Adam 옵티마이저를 사용함.
3.4.1 Time Complexity Analysis:

온라인 서비스는 실시간 추천을 요구함 -> 추론 중 계산 비용이 훈련 단계의 계산 비용보다 중요함.
경험적으로, Amazon-Book 데이터 세트의 모든 테스트 인스턴스에 대해 모델 당 소요 시간.
| FM | NFM | CFKG | CKE | GC-MC | KGAT | MCRec | RippleNet |
| 700s | 780s | 800s | 420s | 500s | 560s | 20시간 | 2시간 |
KGAT는 SL 모델(FM 및 NFM) 및 정규화 기반 방법(CFKG 및 CKE)과 유사한 계산 복잡성을 달성하며, 경로 기반 방법(MCRec 및 RippleNet)보다 훨씬 효율적입니다.
4 Experiments
실험파트에서는 크게 세가지 질문을 갖고 실험을 진행했음.
RQ1: KGAT모델의 기존 sota knowledge-aware recommendation에 비교했을 때 성능
RQ2: KGAT의 각 요소(embedding, attention mechanism, aggregator)등이 미치는 영향
RQ3: KGAT이 reasonable explanation을 주는가?
'kdd > knowledge graph 논문 리뷰' 카테고리의 다른 글
| [KG_2022]ReMR 간단 정리 (0) | 2024.07.28 |
|---|---|
| [강화학습]PGPR과 ReMR을 읽기 위한 base (0) | 2024.07.28 |
| [KG]PGPR을 읽고 ReMR을 읽으면서 느낀 둘 사이의 연관성 (2) | 2024.07.22 |
| [KG_2019]KPRN(Explainable Reasoning over Knowledge Graphs for Recommendation) (1) | 2024.07.22 |
| [KG_2019]PGPR(Reinforcement Knowledge Graph Reasoning forExplainable Recommendation) (8) | 2024.07.21 |

