
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 프로그래머스
- knowledge
- 그래프
- 자료구조
- 백준
- isalpha()
- DP
- 동적 프로그래밍
- bfs
- Algorithm
- 추천시스템
- 그래프 탐색
- kg
- 파이썬
- isdigit()
- Python
- Recommendation
- Dynamic Programming
- Deque
- 정렬
- Knowledge graph
- isnumeric()
- explainable recommendation
- find()
- 우선순위 큐
- 알고리즘
- Stack
- isalnum()
- 코테
- LSTM
- Today
- Total
데린이 고인물되기
[강화학습]PGPR과 ReMR을 읽기 위한 base 본문
https://www.youtube.com/watch?v=AHCt4Phgn9k&list=PL_iJu012NOxehE8fdF9me4TLfbdv3ZW8g&index=21
https://www.youtube.com/watch?v=3Ch14GDY5Y8&list=PL_iJu012NOxehE8fdF9me4TLfbdv3ZW8g&index=2
MDP(Markov Decision Process)
state, action,
policy : \(P(a_t|s_t)\). \(s_t\)에서 어떤 action을 할지에 대한 분포. action을 결정하는것이 policy
transition probability : \(P(s_2|s_1,a_1)\)
강화학습의 goal = maximize Reward = maximize return = maximize Expected Return
return \(G_{t}\triangleq R_{t}+\gamma R_{t+1}+\gamma^{2}R_{t+2}+\cdot\cdot\)
- \(R_t\) : \(a_t\)라는 action을 했을 때 받는 reward
- \(\gamma\) : [0,1]
- 좀 더 효율적인 path를 찾게 해줌.( Q-learning 방식에서 설명함.(1-2강 15분정도))
- 현재 vs 미래 reward
- 1에 가까우면 미래에 받을 reward에 대해 많이 고려
- 0에 가까우면 미래에 대한 reward를 많이 생각하지 않음
- 다시 말해 저 return \(G_t\)의 기댓값을 maximize하는 policy를 찾는 것이 목표
- expected return를 잘 표현하는 2가지 방법이 있음
- 1. state value function : 지금부터(지금 state로부터) 기대되는 return.즉 지금 현재 state에 대한 평가라고 볼 수 있음. 지금 현재 상태의 가치를 매기는 것.
- 2. action value function : 지금 행동으로부터 기대되는 return. 지금 state에서 어떤 action을 할건데, 이 action을 했을 떄 기대되는 return
- optimal policy
- : state value function(지금 state로부터 기대되는 return)을 maximize하는 policy. 과거는 잊고, 잘했다고 치고 지금부터 기대되는 리턴을 최대한 키우는 정책.
수식적으로 들어가보자
* 기댓값 : \(E[x] = \int xp(x) dx\)
\(E[f(x)] = \int f(x)p(x) dx\)
$$return \, G_{t}\triangleq R_{t}+\gamma R_{t+1}+\gamma^{2}R_{t+2}+\cdot\cdot$$
- State value function: 지금부터 기대되는 return
- $$V(s_t) \triangleq \int_{a_t : a_\infty} G_t \, p(a_t,s_{t+1},a_{t+1}\cdot\cdot\cdot\mid s_t)d_{a_t : a_\infty}$$
- return의 기댓값이니까 \(E[f(x)] = \int f(x)p(x) dx\) 여기서 \(f(x)\)에 \(G_t\)들어간거임
- 지금 state에서 이런 저런 action 다해보고 거기서 또 갈 수 있는 state 다 가보고 쭉 쭉 무한대로 가서 다 접근해봤을 때 기대되는 return을 의미.
- 이 State Value function을 maximize하는 \(P(a_t\mid s_t),P(a_{t+1}\mid s_{t+1})\cdot\cdot\cdot P(a_{\infty}\mid s_{\infty}) \)가 Optimal policy
- \( p(a_t,s_{t+1},a_{t+1}\cdot\cdot\cdot\mid s_t) \)를 베이지안 rule로 다 풀어쓰면 \(P(a_t\mid s_t),P(a_{t+1}\mid s_{t+1})\cdot\cdot\cdot P(a_{\infty}\mid s_{\infty}) \) 이것들이 들어가 있음.
- $$V(s_t) \triangleq \int_{a_t : a_\infty} G_t \, p(a_t,s_{t+1},a_{t+1}\cdot\cdot\cdot\mid s_t)d_{a_t : a_\infty}$$
- Action value function : 지금 행동으로부터 기대되는 retun
- $$Q(s_t, a_t) \triangleq \int_{s_{t+1} : a_\infty} G_t\,P(s_{t+1},a_t,s_{t+2},a_{t+2}\cdot\cdot\cdot\mid s_t,a_t)d_{s_{t+1} : a_\infty}$$
- 어떤 \(s_t\)에서 \(a_t\)를 했을 때 그 action에 대한 expected return값.
- $$Q(s_t, a_t) \triangleq \int_{s_{t+1} : a_\infty} G_t\,P(s_{t+1},a_t,s_{t+2},a_{t+2}\cdot\cdot\cdot\mid s_t,a_t)d_{s_{t+1} : a_\infty}$$
벨만 방정석
- 베이지안 rule써서 식전개 해서 state value function을 action value function으로 표현한 식
- $$\begin{aligned} V(s_t) &\triangleq \int_{a_t : a_\infty} G_t \, p(a_t,s_{t+1},a_{t+1}\cdot\cdot\cdot\mid s_t)d_{a_t : a_\infty} \\& =\int_{a_t} \int_{s_{t+1} : a_\infty} G_t\,P(s_{t+1},a_t,s_{t+2},a_{t+2}\cdot\cdot\cdot\mid s_t,a_t)d_{s_{t+1} : a_\infty}P(a_t\mid s_t) d_{a_t} \\&= \int_{a_t}Q(s_t,a_t)P(a_t\mid s_t)d_{a_t} \end{aligned}$$
- 즉 , Q라는 것을 action에 대해 평균을 취한것이 V다.
- 즉, 지금 state에서 기대되는 return(V)은 그 state에서 나가는 각 action들에 대해 기대되는 return(Q)들의 평균값이다
- 즉 , Q라는 것을 action에 대해 평균을 취한것이 V다.
- $$\begin{aligned} V(s_t) &\triangleq \int_{a_t : a_\infty} G_t \, p(a_t,s_{t+1},a_{t+1}\cdot\cdot\cdot\mid s_t)d_{a_t : a_\infty} \\& = \int_{a_t,s_{t+1}}\int_{a_{t+1}:a_{\infty}}G_t\,P(a_{t+1},\cdot\cdot\cdot\mid s_{t+1})d_{a_{t+1}:a_{\infty}}P(a_t,s_{t+1}\mid s_t)d_{a_t,s_{t+1}} \\&=\int_{a_t,s_{t+1}}\int_{a_{t+1}:a_{\infty}}(R_t + \gamma\,G_{t+1})\,P(a_{t+1},\cdot\cdot\cdot\mid s_{t+1})d_{a_{t+1}:a_{\infty}}P(a_t,s_{t+1}\mid s_t)d_{a_t,s_{t+1}} \\&=\int_{a_t,s_{t+1}}(R_t + \gamma\,V(s_{t+1}))P(a_t,s_{t+1}\mid s_t)d_{a_t} \\&= \int_{a_t,s_{t+1}}(R_t + \gamma\,V(s_{t+1}))P(s_{t+1}\mid s_t,a_t)P(a_t|s_t)d_{a_t} \\& where\,\,P(s_{t+1}\mid s_t,a_t)\,\, is\,\,\, transition, P(a_t\mid s_t) \,\,is \,\,\,policy \end{aligned}$$
- V안에 policy도 숨어있음. 즉, V를 최대화 하는 policy를 찾는건데 그게 optimal policy
- 같은 방식으로 action value function도 전개해보면 state value function으로 표현할 수 있음(식은 생략하겠음 쓰기 너무 힘듦..)
- 또 action value function( \(Q(s_t,a_t)\) )을 다른 방식으로 전개해보면 \(Q(s_t,a_t)\)가 \(Q(s_{t+1},a_{t+1})\), t+1에서 policy, transition으로 표현됨.
Optimal Policy : state value function을 maximize하는 policy
$$\begin{aligned} V(s_t) &\triangleq \int_{a_t : a_\infty} G_t \, p(a_t,s_{t+1},a_{t+1}\cdot\cdot\cdot\mid s_t)d_{a_t : a_\infty} \\&=\int_{a_t}Q(s_t,a_t)P(a_t\mid s_t)d_{a_t} \end{aligned}$$
- 여기서 저 식을 maximize하는 \(P(a_t\mid s_t)\)를 찾으면 됨.
- $$\begin{aligned} \underset{P(a_t\mid s_t)} {\mathrm{argmax}} \int_{a_t}Q(s_t,a_t)P(a_t\mid s_t)d_{a_t} \end{aligned}$$
- 3-1강. Optimal policy 쉬운 설명 강의 참고
위에까지는 계속 value-based 설
10-2강. Policy-based
policy-based 의 목표 : expected return을 최대화 하고자 함. state value, action value function이렇게 나누지 않음
$$return \, G_{0}\triangleq R_{0}+\gamma R_{1}+\gamma^{2}R_{2}+\cdot\cdot$$
- \(J \triangleq E(G_0)\)를 maximize 하고 싶다.
- \(s_0,a_0\)에 대해 \(R_0\)얻고, \(s_1,a_1\)에 대해 \(R_1\)얻고, \(s_2,a_0\)에 대해 \(R_2\)얻고,....이렇게 모든 random variable에 대해 다 평균을 취해야 J를 얻을 수 있음.
- $$J \triangleq E(G_0) = \int_{s_0,a_0,s_1,a_1\cdot\cdot\cdot}G_0P_{\theta}(s_0,a_0,s_1,a_1,\cdot\cdot\cdot)d_{s_0,a_0,s_1,a_1,\cdot\cdot} = \int_{\tau}G_0 P(\tau)d_{\tau}$$
- \(\tau = s_0,a_0,s_1,a_1\cdot\cdot\cdot \) 라고 표현하겠음
- \( P_{\theta}(s_0,a_0,s_1,a_1,\cdot\cdot\cdot) \)에 policy \(P_{\theta}(a_0\mid s_0), P_{\theta}(a_1\mid s_1) \cdot\cdot\) 다 들어있음.
- J를 maximize하고 싶다!
- 저 policy의 파라미터 \(\theta\)를 찾고자 함.
- 이제 저 J 라는 objective function을 최대화 하는 파라미터를 gradient ascent방식으로 그냥 찾으면 됨.
- \(\theta \leftarrow \theta + \alpha \bigtriangledown_\theta J_\theta\)
- 본격적으로 policy gradient 하는 방법 설명 : https://www.youtube.com/watch?v=t9wuRUFWkRQ&list=PL_iJu012NOxehE8fdF9me4TLfbdv3ZW8g&index=23
Policy-based 알고리즘 중 하나인 REINFORCE 알고리즘
- \(\theta \leftarrow \theta + \alpha \bigtriangledown_\theta J_\theta\) 에서 \( \bigtriangledown_\theta J_\theta \) 식 전개를 해보면 기댓값 구하는 형태로 식 전개를 할 수 있음.

저렇게 식 정리를 할 수 있는데,

저렇게 기댓값 참고 식에서 x부분이 sample. 즉, \(s_0, a_0, s_1, a_1...\) 를 여러번 샘플링 해서 평균 낸게 저 \( \bigtriangledown_\theta J_\theta \) 로 취급할 수 있는거임. 여러번 샘플링(N번) 하면 N으로 나누는건데, 이게 한번 샘플링할 때, t가 0부터 무한대까지니까(무한대는 아니라도 겁나 길다) 할게 너무 많아서 REINFORCE 알고리즘은 이 샘플링을 그냥 1번 하는거임. N을 1로 하는거.그렇게 정책 파라미터를 업데이트 해주는걸 반복해주는 알고리즘.
그래서 과정을 보면
- 0. \(\theta\) 초기화
1. ~2 반복 - 1. Get \(\tau\) from \(P_{\theta}(a_t\mid s_t)\) -> 샘플을 얻음
- 2. 얻은 샘플로 \(\theta\) 업데이트.
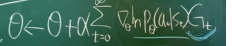
RENINFORCE는 bias는 없지만,(sample이 믿을만 하지만), variance가 매우 큼. variance를 줄이기 위해서 PGPR에서 채택한 방식이 value network값을 뺴준 것 같음.
[강화학습] 허구한 날 까먹는 Policy gradient theorem 정리
재야의 숨은 고수가 되고 싶은 초심자
hiddenbeginner.github.io
REINFORCE 알고리즘이 분산이 크다는 점을 완화하기 위한 알고리즘인 Actor-Critic 알고리즘 직관적으로 이해하기
- \(\theta \leftarrow \theta + \alpha \bigtriangledown_\theta J_\theta\) 에서 \( \bigtriangledown_\theta J_\theta \) 식 전개를 베이지안 rule을 사용해서 해보면,

REINFORCE알고리즘은 G_t가 들어있음. G_t가 있는건 에피소드를 끝까지 터미널까지가야만 모을 수 있는 값이라 결국 끝까지 가야만 한 번 업데이트가 가능했음.
Actor critic은 저렇게 수식 전개를 해보니까 Q(action value function)이 나옴. -> 아래 이미지 식을 sample한다고 했을 때, G_t가 필요 없으니까 끝까지 안가봐도 샘플을 구할 수 있음. -> 이렇게 하려면 Q 도 파라미터 화 시켜야 함. 정책도 파라미터 화 하기 때문에 Q도 구해야하고 P도 구해야 해서 actor라는게 있고 critic이라는게 있어서 2개가 동작을 하게 되는 메커니즘임. => G_t를 안쓰기 때문에 variance가 크지 않(터미널까지 가지 않아서 그런듯)
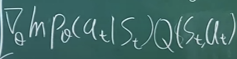
- Actor가 정책, \(P_{\theta}(a_t\mid s_t)\)를 업데이트하는 녀석. critic이 actor의 action을 평가하면 그걸 가지고 정책 업데이트.
- Critic은 Q_{w}()를 업데이트함 (W는 파라미터.) : actor의 action에 대한 평가를 매김
[Actor-Critic]
0. initialize \(\theta, w\)
매 step마다 아래 과정 반복.(REINFORCE는 매 step 마다가 아닌 하나 에피소드가 끝나면 그 에피소드로 업데이트함.)
1. Actor update

2. Critic update
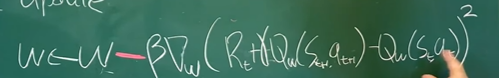
이건, biased, low-variance임.
'kdd > knowledge graph 논문 리뷰' 카테고리의 다른 글
| [KG_2022]ReMR 간단 정리 (0) | 2024.07.28 |
|---|---|
| [KG_2019]KGAT: Knowledge Graph Attention Network for Recommendation (0) | 2024.07.24 |
| [KG]PGPR을 읽고 ReMR을 읽으면서 느낀 둘 사이의 연관성 (2) | 2024.07.22 |
| [KG_2019]KPRN(Explainable Reasoning over Knowledge Graphs for Recommendation) (1) | 2024.07.22 |
| [KG_2019]PGPR(Reinforcement Knowledge Graph Reasoning forExplainable Recommendation) (8) | 2024.07.21 |

