
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 파이썬
- Python
- 추천시스템
- DP
- 그래프
- isnumeric()
- isdigit()
- knowledge
- 정렬
- 프로그래머스
- find()
- LSTM
- 알고리즘
- Recommendation
- Algorithm
- 우선순위 큐
- 코테
- 자료구조
- 동적 프로그래밍
- Stack
- isalpha()
- Knowledge graph
- kg
- bfs
- explainable recommendation
- 그래프 탐색
- Dynamic Programming
- isalnum()
- Deque
- 백준
- Today
- Total
데린이 고인물되기
[KG_2019]PGPR(Reinforcement Knowledge Graph Reasoning forExplainable Recommendation) 본문
[KG_2019]PGPR(Reinforcement Knowledge Graph Reasoning forExplainable Recommendation)
데린이 성장 중 2024. 7. 21. 22:14일논문 읽기 전, 대략적인 내용 파악
1. 서론
최근 개인화 추천 시스템에서는 지식 그래프(Knowledge Graph, KG)의 구조화된 정보를 활용한 연구가 활발히 진행되고 있다. 대부분의 기존 연구는 더 정확한 추천을 위해 지식 그래프를 활용하는 데 중점을 두지만, 본 논문에서는 명시적인 지식 추론을 통해 추천을 생성하고 이를 해석 가능한 인과 추론 절차로 지원하는 방법을 제안한다. 이를 위해 정책 기반 경로 추론(Policy-Guided Path Reasoning, PGPR) 방법을 제안하며, 추천과 해석 가능성을 결합하여 실제 경로를 제공한다.
핵심 키워드: 지식 그래프, 개인화 추천, 정책 기반 경로 추론, 해석 가능성
2. 연구 문제 및 방법
기존의 KG 기반 추천 방법은 주로 KG 임베딩 모델을 사용하여 벡터 공간에서 유사성을 계산하거나, 경로 기반 접근 방식을 사용하여 다중 관계 경로를 탐색하는 데 중점을 두었다. 그러나 이러한 접근 방식은 대규모 KG에서의 관계와 엔티티의 다양성을 다루기 어려운 문제가 있다.(니중에 찾아서 공부해봐야겠다) 본 연구는 강화 학습(Reinforcement Learning, RL)을 활용하여 명시적 경로 추론을 통해 추천을 생성하고 이를 해석 가능한 방식으로 제공하는 방법을 제안한다. 제안된 PGPR 방법은 사용자 조건부 행동 가지치기와 멀티 홉 스코어링 기능을 포함한 혁신적인 소프트 보상 전략을 특징으로 한다.
핵심 키워드: KG 임베딩, 강화 학습, 경로 추론, 사용자 조건부 행동 가지치기
3. 연구 결과 및 해석
제안된 PGPR 방법은 아마존의 여러 대규모 실제 데이터셋에서 평가되었으며, 최신 방법들과 비교하여 우수한 성능을 보였다. 특히 NDCG, Recall, Hit Rate, Precision 등의 대표적인 추천 지표에서 일관되게 높은 성과를 나타냈다. 예를 들어, CD & Vinyl 데이터셋에서 JRL 대비 NDCG가 3.94% 향상되었고, Clothing 데이터셋에서는 64.73%의 상당한 개선이 있었다. 이러한 성과는 지식 그래프의 다중 홉 상호작용을 효과적으로 포착하는 경로 추론 과정 덕분이다. 또한, 추천된 아이템마다 평균 1.6개의 추론 경로가 발견되어 다수의 경로가 추천 증거로 제공될 수 있음을 보여준다.
핵심 키워드: 성능 평가, NDCG, Recall, Hit Rate, Precision, 다중 홉 상호작용
4. 결론 및 제언
본 논문은 명시적인 경로 추론을 통해 해석 가능한 추천 시스템을 구현하는 PGPR 방법을 제안하였다. 실험 결과, 제안된 방법은 높은 추천 성능과 더불어 추천 이유를 명확히 설명할 수 있는 경로를 제공함으로써 시스템의 투명성을 높인다. 향후 연구로는 PGPR 접근 방식을 제품 검색, 소셜 추천 등 다른 그래프 기반 작업에 확장하거나, 시간에 따라 변하는 그래프를 모델링하여 동적 의사결정 지원을 제공하는 방향을 제안한다.
핵심 키워드: 투명성, 경로 추론, 동적 의사결정, 그래프 기반 작업
종합 요약
본 논문에서는 개인화 추천 시스템에서 해석 가능성과 성능을 동시에 향상시키기 위해 강화 학습 기반의 정책 가이드 경로 추론 방법(PGPR)을 제안하였다. PGPR은 사용자 조건부 행동 가지치기와 멀티 홉 스코어링 기능을 통해 지식 그래프를 활용한 명시적 경로 추론을 수행하며, 아마존 데이터셋에서의 실험을 통해 기존 최신 방법들보다 우수한 성능을 입증하였다. 이로써 추천 결과의 투명성을 높이고, 다양한 응용 분야로 확장 가능성을 제시하였다.
Abstract
- 개인화된 추천에 대한 최근의 발전은 지식 그래프가 제공하는 풍부한 구조화된 정보를 활용하는 것에 큰 관심을 불러일으켰습니다. 대부분의 기존 접근 방식이 더 정확한 추천을 위해 지식 그래프를 활용하는 것에만 중점을 두는 것과 달리, 우리는 의사결정을 위한 명시적 추론을 수행하여 추천이 해석 가능한 인과 추론 절차에 의해 생성되고 지원되도록 합니다.
- 이를 위해, 우리는 지식 그래프에서 실제 경로를 제공함으로써 추천과 해석 가능성을 결합하는 방법인 Policy-Guided Path Reasoning (PGPR)을 제안합니다.
- 우리의 기여는 네 가지 측면으로 요약될 수 있습니다.
- 첫째, 추천 문제에 지식 그래프를 포함시키는 것의 중요성을 강조하고 추론 과정을 공식적으로 정의하고 해석합니다.
- 둘째, 혁신적인 소프트 보상 전략, 사용자 조건부 액션 가지치기 및 다중 홉 스코어링 기능을 갖춘 강화 학습(RL) 접근 방식을 제안합니다.
- 셋째, 추천을 위한 추론 경로를 효율적이고 효과적으로 샘플링하기 위해 정책 가이드 그래프 탐색 알고리즘을 설계합니다.
- 마지막으로, 여러 대규모 실제 벤치마크 데이터 세트에서 우리의 방법을 광범위하게 평가하여 최첨단 방법과 비교할 때 유리한 결과를 얻습니다.
- 요약 및 정리
- 최근 개인화된 추천 시스템에서는 지식 그래프를 활용하여 더 정확하고 해석 가능한 추천을 생성하는 방법에 대한 연구가 활발히 이루어지고 있음.
- 이 논문에서는 "정책 기반 경로 추론 (Policy-Guided Path Reasoning, PGPR)"이라는 방법을 제안함.
- 이 방법은 지식 그래프를 통해 명시적인 추론을 수행함 ->
- 추천의 해석 가능성을 높임.
- PGPR은 강화 학습을 기반으로 하며,
- 소프트 보상 전략, 사용자 조건부 액션 가지치기, 다중 홉 스코어링 함수를 특징으로 함
- 추천을 위한 추론 경로를 효율적이고 효과적으로 샘플링하기 위해 정책 가이드 그래프 탐색 알고리즘을 설계함.
- 여러 대규모 실제 데이터 세트를 통해 PGPR의 효과를 입증하였으며, 기존 최첨단 방법들보다 우수한 결과를 얻었음.
- 이 방법은 지식 그래프를 통해 명시적인 추론을 수행함 ->
[보충 설명]
- 해석 가능한 추천
- : 대부분 기존의 추천시스템은 추천 이유를 명확하게 설명하지 못함.
- PGPR은 추천 과정에서 지식그래프와 강화학습(지식 그래프 내에서 최적의 경로를 탐색하고 학습하는데 사용)을 사용해 추천 과정에서 명시적인 경로 추론을 통해 추천 이유를 사용자에게 설명할 수 있음.
- 강화학습 접근법
- PGPR은 강화학습을 통해 사용자와 항목 간의 최적 경로를 학습. -> 각 추천이 왜 이루어졌는지에 대한 명확한 경로 제공이 가능
- 소프트 보상 전략
- 추천의 정확도를 높이기 위해 도입
- 다양한 경로를 탐색하면서도 사용자가 관심을 가질만한 항목을 효율적으로 추천할 수 있게 함
- 사용자 조건부 액션 가지치기
- 그래프 내의 액션 공간이 매우 클 때, 사용자가 관심을 가질 가능성이 낮은 경로를 가지치기해 탐색 효율성을 높임
- 다중 홉 스코어링
- 여러 단계를 거쳐 연결된 엔티티 간의 관계를 평가 하여, 더 깊이 있는 추천을 가능하게 함
1. Introduction
- 추천 시스템 with KG(지식 그래프)
- => 다양한 구조화된 정보를 더 잘 활용하여 추천 성능을 향상시킬 수 있음
- => 엔티티 간의 관계를 직관적으로 이해하기 쉬워짐 -> 추천 모델의 해석 가능성 향상
- 최근 연구자들 : 개인화된 추천에서 지식 그래프 추론의 잠재력을 탐구함
- 연구방향 1) TransE 및 node2vec와 같은 지식 그래프 임베딩 모델을 사용하여 추천을 만드는 것에 중점을 둠
- : 지식 그래프를 정규화된 벡터 공간에 정렬하고 엔티티 간의 표현 거리 계산을 통해 유사성을 밝혀냄
- 단점 : 순수 KG 임베딩 방법은 다중 홉 관계 경로를 발견할 수 없음.
- 논문 [1]에서 개인화된 추천을 위해 KG임베딩에 대한 협업 필터링(CF) 방법을 향상시키고, 사용자와 항목 간의 설명 경로를 찾기 위해 소프트 매칭 알고리즘을 제안했으나,
이 전략의 한 가지 문제는 설명이 추론 과정에 따라 생성되지 않고 사용자와 항목 임베딩 간의 경험적 유사성 매칭을 통해 나중에 생성된다는 것임.
따라서, 그들의 설명 구성 요소는 이미 선택된 추천에 대한 사후 설명(post-hoc explanation)을 찾으려고 시도하는 것에 불과함
- 논문 [1]에서 개인화된 추천을 위해 KG임베딩에 대한 협업 필터링(CF) 방법을 향상시키고, 사용자와 항목 간의 설명 경로를 찾기 위해 소프트 매칭 알고리즘을 제안했으나,
- 연구 방향 2) 경로 기반 추천을 조사함.
- 예를 들어, 논문 [4]에서는 KGs에 대한 추론을 위해 메타 경로 개념을 제안함.
- 그러나 이 접근 방식은 대규모 실제 KGs에서 다양한 유형의 관계 및 엔티티를 처리하는 데 어려움을 겪고 있으며, 따라서 연결되지 않은 엔티티 간의 관계를 탐색할 수 없음.
- Wang 등[28]은 user-item pair 간의 모든 자격 경로(qualified path)를 열거한 후 추출된 경로에서 순차적 RNN 모델을 훈련시켜 쌍의 순위 점수를 예측하는 경로 임베딩 접근 방식을 최초로 개발함.
- 추천 성능은 더욱 향상되었지만 대규모 KGs에서 각 user-item pair에 대한 모든 경로를 완전히 탐색하는 것은 실용적이지 않음
- 예를 들어, 논문 [4]에서는 KGs에 대한 추론을 위해 메타 경로 개념을 제안함.
-
더보기그러니까 한줄 요약하면, 기존 연구들은 주로 KG 임베딩 모델을 사용하거나경로 기반 추천을 조사했는데, 이 접근 방식들은 다중 홉 경로를 발견하는 데 한계가 있었음
-> 그래서 이 논문에서 제안한게 PGPR방법( RL과 KG를 결합 )
-> 추천 과정이 명확히 해석될 수 있고 추천 성능을 최적화할 수 있음.
- 연구방향 1) TransE 및 node2vec와 같은 지식 그래프 임베딩 모델을 사용하여 추천을 만드는 것에 중점을 둠
- 우리는 지능형 추천 agent가 유사성 매칭을 위해 그래프를 단순히 잠재 벡터로 임베딩하는 것이 아니라,
의사 결정을 위해 지식 그래프를 통해 명시적인 추론을 수행하여 의사결정을 내릴 수 있는 능력을 가져야 한다고 믿음. - 이 논문에서 지식 그래프를 사용자, item, 기타 엔티티 및 이들의 관계에 대한 에이전트의 지식을 유지하기 위한 다목적 구조로 간주함. 에이전트는 user에서 시작해서 그래프에 대해 명시적인 multi-step path 추론을 수행해 그래프에서 적합한 항목을 찾아 target user에게 추천함.
- 기본 아이디어는 에이전트가 명시적 추론 경로를 기반으로 결론을 도출하면, 각 추천에 이르는 추론 과정을 해석하기 쉽다는 것입니다.
- 따라서 시스템은 추천 항목을 지원하는 인과 증거를 제공할 수 있음. 이에 따라 우리의 목표는 추천을 위한 후보 항목 집합을 선택하는 것뿐만 아니라 주어진 추천이 이루어진 이유에 대한 해석 가능한 증거로 그래프에서 해당 추론 경로를 제공하는 것임.
- 예를 들어(그림 1), user A가 주어지면 알고리즘은 그래프에서 {User A → Item A → Brand A → Item B} 및 {User A → Feature B → Item F}와 같은 추천 경로와 함께 후보 item B 및 F를 찾아야 합니다.
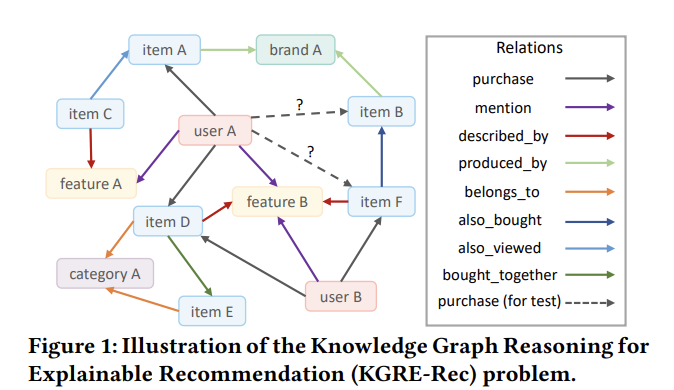
- 이 논문에서는 이전 작업의 단점을 극복하는 접근 방식을 제안한.
- 구체적으로, 우리는 추천 문제를 지식 그래프에 대한 결정론적 MDP로 설명함.
- 우리는 강화 학습 접근 방식을 채택하여 경로 이력(path history)이 사용자에게 항목이 추천되는 이유에 대한 설명으로 수행됨.
- 강화 학습 접근 방식 : 에이전트가 주어진 user에서 시작하여 관심 item으로 이동하는 방법을 배움
- 우리는 강화 학습 접근 방식을 채택하여 경로 이력(path history)이 사용자에게 항목이 추천되는 이유에 대한 설명으로 수행됨.
- 구체적으로, 우리는 추천 문제를 지식 그래프에 대한 결정론적 MDP로 설명함.
- 주요 과제는 세 가지가 있다
- user를 위해 item의 정확성을 측정하는 것은 어려운 일임
- -> 종료 조건(terminal condition) 및 RL 보상을 신중히 고려해야 함
- 문제를 해결하기 위해 우리는 다중 홉 scoring function을 기반으로 한 소프트 보상 전략을 설계함(=>KG의 풍부한 heterogeneous 정보를 활용함)
- 여기서 말하는 heterogeneous는 heterogeneous graph를 의미하는 듯 ( https://ysg2997.tistory.com/41 )
-
더보기이건 그냥 서치하다가 찾은 논문인데 나중에 읽어보면 좋을 듯 하다(https://ysg2997.tistory.com/41)
이 논문 리뷰하면 링크는 (여기 넣어둘거임 ㅇㅇ)
-
- 여기서 말하는 heterogeneous는 heterogeneous graph를 의미하는 듯 ( https://ysg2997.tistory.com/41 )
- user를 위해 item의 정확성을 측정하는 것은 어려운 일임
-
- 그래프의 out-degrees에 따라 액션 공간의 크기가 결정되므로, 그 값이 일부 노드에 대해 매우 클 수 있음
- -> 그래프에서 유망한 추론 경로를 찾기 위한 효율적인 탐색이 중요. 이를 위해, 우리는 추천 성능을 보장하면서 액션 공간의 크기를 줄이기 위해 사용자 조건부 액션 가지치기 전략( user-conditional action pruning strategy )을 제안함.
-
더보기그래프의 out-degree : 방향 그래프에서 node를 나가는 edge의 수
https://yoongrammer.tistory.com/83
- 에이전트가 추천을 위해 그래프를 탐색할 때 item과 경로의 다양성을 보존해야 하므로 제한된 item 영역에 갇히지 않도록 해야 함.
- -> 이를 위해 우리는 추론 단계에서 추천을 위한 추론 경로를 샘플링하기 위해 정책 가이드 검색 알고리즘( policy-guided search algorithm )을 설계함. 우리는 추천을 위한 설명의 다양성을 질적으로 평가하기 위해 여러 사례 연구를 수행했음.
- 이 논문의 주요 기여는 다음과 같이 요약할 수 있다.
- 추천 문제에 풍부한 heterogeneous 정보를 통합하여 추론 과정을 공식적으로 정의하고 해석하는 것의 중요성을 강조
- 소프트 보상 전략( soft reward strategy ), 사용자 조건부 액션 가지치기( user-conditional action pruning) 및 다중 홉 스코어링 전략( multi-hop scoring strategy)에 의해 구동되는 RL 기반 접근 방식을 제안함.
- 추천을 위한 다양한 추론 경로와 후보 item 집합을 효율적으로 샘플링하기 위해 policy 네트워크에 의해 안내되는 빔 검색 기반 알고리즘( beam search-based algorithm )을 설계함.
- 여러 아마존 전자 상거래 도메인에서 우리의 방법의 효과를 광범위하게 평가하여 강력한 결과와 해석 가능한 추론 경로를 얻음.
2 RELATED WORK
2.1 Collaborative Filtering
- 협업 필터링(CF) : 추천을 위한 가장 기본적인 접근 방식 중 하나.
- 초기 CF 접근 방식은 user-item rating matrix를 만들고 user based 또는 item based 협업 필터링 방법을 통해 평점을 예측했음.
- 차원 축소 방법이 발전하면서 matrix factorization(행렬 분해) 같은 잠재 요인 모델이 추천시스템에서 널리 채택됨.
- 특정 기술에는 특이값 분해(SVD)[12], non-negative matrix factorization[13] 및 probabilistic matrix factorization[14] 가 포함됨. 이러한 접근 방식은 기본으로 각 user와 item에 대해 잠재 요인 표현을 학습하여 user-item 쌍의 matching score를 계산한다.
- 최근에는 딥러닝 및 신경 모델이 협업 필터링을 더욱 확장시킴.
- 크게 두가지 하위 범주로 분류 됨.
- similarity learning approach(유사성 학습 접근 방식)
- 비교적 간단한 user/item 임베딩(e.g., one-hot vectors)을 채택
- user-item matching scores를 계산하기 위한 similarity function으로 복잡한 예측 네트워크를 학습함
- representation learning approach(표현 학습 접근 방식)
- 훨씬 더 풍부한 user/item 표현을 학습하지만,
- score matching을 위해 간단한 similarity function(e.g., inner product)을 채택
- similarity learning approach(유사성 학습 접근 방식)
- 크게 두가지 하위 범주로 분류 됨.
- 차원 축소 방법이 발전하면서 matrix factorization(행렬 분해) 같은 잠재 요인 모델이 추천시스템에서 널리 채택됨.
- 그러나 잠재 요인 또는 잠재 표현 모델에서 추천 결과를 설명하는 데 어려움을 겪고 잇으며, 해석 가능한 추천이 중요한 연구 문제임을 인식함
2.2 Recommendation with Knowledge Graphs
- 이전에 일부 연구는 지식 그래프 임베딩의 도움을 받아 사용자에게 추천을 제공했음
- ex1) 추천 성능을 향상시키기 위해 지식 그래프 임베딩을 풍부한 콘텐츠 정보로 활용함.
- 예를 들어, 논문 [30]은 지식 베이스 임베딩을 채택 -> 추천을 위한 user 및 item 표현을 생성함
- 논문 [10]에서는 추천을 위해 지식 그래프 엔티티 임베딩에 대한 메모리 네트워크를 사용함.
- 논문 [26]에서는 embedding-guided multi-hop KG 기반 추천을 위한 ripple network 접근 방식을 제안함.
- ex1) 추천 성능을 향상시키기 위해 지식 그래프 임베딩을 풍부한 콘텐츠 정보로 활용함.
- 다른 연구 방향은 지식 그래프의 엔티티 및 경로 정보를 활용하여 해석 가능한 결정을 내리는 것.
- 예를 들어, 논문 [1]은 해석 가능한 추천을 위해 지식 그래프 임베딩 학습을 통합함.
- 그러나 그들의 설명 경로는 본질적으로 사후 설명( post-hoc explanations )이며, 설명은 해당 item이 선택된 후 소프트 매칭에 의해 생성됨
- [28] 에서는 추천에서 KGs에 대한 추론을 위해 RNN 기반 모델을 제안함.
- 그러나 이 모델은 학습 및 예측을 위해 각 user-item 쌍 간의 가능한 모든 경로를 열거해야 하므로 대규모 지식 그래프에서는 비현실적일 수 있.
- 예를 들어, 논문 [1]은 해석 가능한 추천을 위해 지식 그래프 임베딩 학습을 통합함.
2.3 Reinforcement Learning
- 최근 몇 년 동안 알파고(AlphaGo)와 같은 딥 RL 접근 방식의 성공적인 응용이 시리즈로 발표됨
- => 환경을 더 잘 이해하고 고수준의 인과 관계를 추론할 수 있는 능력을 보여줌.
- 광고 추천, 뉴스 추천 및 사후 해석( post-hoc explainable ) 가능한 추천과 같은 non-KG settings에서 추천 시스템에 RL을 적용하려는 시도가 있었음.
- 동시에 연구자들은 다른 작업에 대한 KG settings에서 RL을 탐구하기도 함
- ex. 질문 응답(QA)을 위한 다중 홉 추론을 순차적 의사 결정 문제로 공식화했음.[3, 14, 29]
- 논문 [29]은 경로 찾기를 위해 강화 학습을 활용
- [3]은 다중 홉 KG 질문 응답을 위한 모델을 훈련하는 MINERVA라는 시스템을 제안함
- [14] 보상 형성(reward shaping) 및 액션 드롭아웃(action dropout)을 사용하여 end-to-end RL-based KG question answering을 위한 모델을 제안했습니다.
- 그러나 우리가 아는 한, 추천 작업을 위해 KG에서 RL을 활용한 이전 작업은 없다. 특히 경로 홉 수가 증가함에 따라 KG가 각 엔터티 노드에 대해 매우 큰 action space을 가질 떄 더욱 그렇다.
- ex. 질문 응답(QA)을 위한 다중 홉 추론을 순차적 의사 결정 문제로 공식화했음.[3, 14, 29]
3 METHODOLOGY
이 섹션에서는 설명 가능한 추천을 위한 지식 그래프 추론이라는 새로운 추천 문제를 공식화 함. 그런 다음, 지식 그래프에서 강화학습을 기반으로 이 문제를 해결하기 위한 접근법을 제시함.
3.1 Problem Formulation
- 일반적으로, 엔티티 집합 \(\mathcal{E}\) 와 관계 집합 \(\mathcal{R}\) 을 가진 지식 그래프 \(\mathcal{G}\) 는 \({\mathcal{G}}=\{(e,r,e^{\prime})\mid e,e^{\prime}\in{\mathcal{E}},r\in{\mathcal{R}}\}\)로 정의됨.
- 여기서 각 트리플릿 \((e,r,e^{\prime})\)는 헤드 엔티티 \(e\)에서 테일 엔티티 \({\boldsymbol{e}}^{\prime}\)로의 관계 \(r\)의 사실을 나타냄.
- 이 논문에서는 설명 가능한 추천을 위한 특별한 유형의 지식 그래프를 고려하며, 이를 \(\mathcal{G_{\mathrm{{R}}}}\)로 표시함.
- 이 그래프는 사용자 엔티티의 부분 집합 \(\mathcal{U}\) 와 item 엔티티의 부분 집합 \(\mathcal{I}\)를 포함함.
- 여기서 \({\mathcal{U}}.{\mathcal{I}}\subseteq{\mathcal{E}}\operatorname{and}{\mathcal{U}}\cap{\mathcal{I}}=\emptyset\) 임.
- 이 두 종류의 엔티티는 관계 \(r_{u i}\)를 통해 연결됨.
- 그래프 \(\mathcal{G_{\mathrm{{R}}}}\)에서 k-홉 경로를 다음과 같이 정의함
Definition 3.1. (k-hop path)
- 엔티티 \(e_0\)에서 엔티티 \(e_k\)로의 k-hop 경로
- k개의 관계로 연결된 k+1 개의 엔티티의 시퀀스로 정의되며,
- \(p_{k}(e_{0},e_{k}^{-})=\left\{e_{0}\stackrel{r_{1}}{\longleftrightarrow}e_{1}\stackrel{r_{2}}{\longleftrightarrow}\cdot\cdot\cdot\stackrel{r_{k}}{\longrightarrow}e_{k}\right\}\) 이렇게 표시됨.
- 여기서, \(e_{i-1}\stackrel{r_{i}}{\longleftrightarrow}e_{i}\)는 \((e_{i-1},r_{i},e_{i})\in{\mathcal{G}}_{{R}}\) 또는 \((e_{i},r_{i},e_{i-1})\in \mathcal{G}_{\mathrm{R}}\)을 나타내며, \(i\in[k]\) 임.
이제 설명 가능한 추천을 위한 지식그래프 추론(KGRE-Rec) 문제를 다음과 같이 공식화 할 수 있음
Definition 3.2. (KGRE-Rec Problem)
- 지식 그래프 \(\mathcal{G_{\mathrm{{R}}}}\), 사용자 \(u\in U\) 및 정수 \(K\)와 \(N\)이 주어졌을 때, 각 user-item pair \(\left(u,i_{n}\right)\)이 하나의 추론 경로 \(p_k(u,i_{n})\,(2\leq k\leq K)\)와 연결되도록 추천 항목 집합 \(\{i_{n}\}_{n\in[N]}\subseteq \mathcal{I}\)을 찾는 것이 목표.여기서 \(N\)은 추천 수를 의미함.
item 추천과 경로 찾기를 동시에 수행하기 위해, 우리는 세가지 측면을 고려함.
- 특정 사용자에 대한 사전 정의된 targeted items가 없으므로 사용자가 item과 상호작용하는지 여부를 나타내는 이진 보상을 사용하는 것은 적절하지 않음.
- reward function의 더 나은 설계는 KG가 제공하는 풍부한 hegerogeneous 정보를 기반으로 item이 user와 얼마나 관련이 있는지에 대한 불확실성을 통합하는 것이다.
-
더보기위 문장의 의미를 나름대로 생각해보자면..
추천 시스템에서는 user가 어떤 item과 상호작용할 가능성을 평가하여 보상을 부여하는데, 여기서 reward function은 이 상호작용 가능성을 기반으로 item의 추천 여부를 결정함.
그러니까 단순히 "사용자가 항목과 상호작용하였는가"라는 이진보상(예/아니오) 대신, 더 정교한 접근법을 사용해야한다는 말 같다.
- 일부 엔티티의 out-degrees가 매우 클 수 있음 -> user에서 잠재적 item 엔티티로의 경로를 찾는 효율성이 저하됨
- 각 user와 모든 item간의 가능한 모든 경로를 열거하는 것은 매우 큰 그래프에서는 불가능.
- 따라서, 핵심 과제는 reward를 휴리스틱으로 사용해서, 잠재적 item을 향한 관련 경로를 효율적으로 검색하고, edge 가지치기를 효과적으로 수행하는 것이다.
- 모든 user에 대해 추천된 항목에 대한 추론 경로의 다양성이 보장되어야 함.
- 설명 가능한 추천을 제공하기 위해 항상 특정 유형의 추론 경로를 고수하는 것은 합리적이지 않음.
- 하나의 단순한 해결책이 post-hoc recommendation(사후 추천) :
- 먼저 유사성 측정에 따라 후보 항목을 생성하고,
- 그 다음 그래프 내에서, user에서 후보 item으로의 별도의 경로를 찾기 절차를 수행함
- 이러한 사후 추천 방식의 주요한 단점은 추천 프로세스가 지식 그래프의 풍부한 heterogeneous meta-data를 활용하지 못하고, 생성된 경로가 추천 알고리즘에서 채택한 실제 의사 결정 과정과 분리되어 있어서 해석할 수 없다는 것임(해석 가능성을 떨어뜨림).
-
더보기지식 그래프에서 결국 user에서 추천할 아이템까지 가는 경로를 찾는 것 같은데, 왜 꼭 강화학습인지 궁금해서 대충 gpt한테 물어보고 끄적이는 생각..
- 결국 추천할 아이템이 나왔다는건 경로를 따라갔다는건데, 강화학습 적용전에도 kg이용한 추천 시스템은 있었을 텐데, 왜 굳이 사후 에 다시 경로를 찾는지 이해가 안갔음
-> 그냥 강화학습이든 뭐든 일단 그 추천 경로 그거 보면 설명 되는거 아님? 이라고 생각했는데
실제로 경로 기반 방법이라고 meta-paths,pathrank같은 user와 item간의 명시적 경로를 찾아 추천에 활용하는 방식이 있다고 하는데, 명시적 경로를 찾는다는건 걍 그 경로 보면 되는거 아닌가?
-> 아니라고 한다. 이론적으로 사용자가 추천된 항목에 도달하는 경로를 사전 또는 실시간으로 기록할 수있기는 하나, 실제로는 계산 복잡도나 성능 저하 문제 등으로 인해 사후적으로 다시 찾는 것이라고,,
강화학습은 최적의 경로를 찾기위해 모든 가능한 경로를 탐색하는 대신, 학습된 정책을 통해 가장 유망한 경로만을 탐색함. 그리고 reward를 이용해서 경로의 중요도를 평가해 불필요한 경로를 탐색하지 않도록 함.
또한, 동적 학습(에이전트가 환경(사용자 행동 및 선호)의 변화를 실시간으로 반영할 수 있음)이 가능해서 변화하는 추천 기준에 적응도 쉽다.각 사용자의 상태에 기반해 최적의 경로를 동적으로 선택할 수 있어서, 사용자 맞춤형 추천이 가능함. 그리고 액션 공간 가지치기같은 방법을 사용해서 각 사용자의 상태에 적합한 경로만을 탐색해 효율성을 높이는 등의 장점이 있어 강화학습이 추천시스템에서 특히 유용하다고 한다.
다음 섹션에서는 KG를 통한 설명 가능한 추천을 위해 정책 기반 경로 추론 방법(PGPR)을 소개함.
이 방법은 강화학습을 통해 문제를 해결함. KG의 풍부한 heterogeneous정보의 맥락에서 경로를 동시에 검색하면서 추천을 생성.
그림 2에서와 같이, 주요 아이디어는 KG 환경에서 시작 user에 따라 잠재적으로 '좋은' item 으로 이동하는 방법을 학습하는 RL agent를 훈련시키는 것임.
그런 다음, agent를 활용해 각 user에 대한 추천 item으로 이어지는 추론 경로를 효율적으로 샘플링함. 이런 샘플링된 경로는 추천 항목에 대한 설명으로 자연스럽게 작용한다.

3.2 Formulation as Markov Decision Process
- 우리 method의 출발점은 KGRE-Rec 문제를 MDP로 공식화 하는 것이다.
- 경로 연결성을 보장하기 위해 그래프 \(\mathcal{G}_{\mathrm{{R}}}\) 두가지 종류의 특수 edge를 추가함.
- 첫번 째는 역방향 edge. \((e,r,e^{\prime})\in{\mathcal{G}}_{\mathbb{R}}\)이면 \((e^{\prime},r,e)\in{\mathcal{G}}_{\mathbb{R}}\)임. 이건 경로 정의에 사용된다.
- 두번 째는 NO-OP(No Operation)관계와 연관된 self-loop edges. 만약 \({e}\in{\mathcal{E}}\) 이면, \((e,r_{\mathrm{noop}},e)\in{\mathcal{G}}_{\mathrm{R}}\) 임.
-
더보기NOOP(No Operation) 관계 : 실제로 아무런 작업을 수행하지 않는 관계. 즉, 노드의 상태를 변경하지 않는, 아무런 의미가 없는 이동을 의미함.
강화학습 에이전트가 경로를 탐색할 때, 특정 상태에서 이동하지 않고 그대로 유지될 수 있도록 하기 위해 사용됨. 이를 통해 에이전트가 불필요한 이동을 하지 않고도 보상을 받을 수 있음.
-
- 첫번 째는 역방향 edge. \((e,r,e^{\prime})\in{\mathcal{G}}_{\mathbb{R}}\)이면 \((e^{\prime},r,e)\in{\mathcal{G}}_{\mathbb{R}}\)임. 이건 경로 정의에 사용된다.
state
단계 \(t\)에서의 상태 \(s_t\)는 \((u,e_{t},h_{t})\)로 정의됨.
- 여기서 \(u\in U\) 는 시작 사용자 엔티티
- \(e_t\)는 agent가 단계 \(t\)에서 도달한 엔티티,
- \(h_t\)는 \(t\)단계 이전의 이력.
- k-step history는 과거 \(k\)단계의 모든 엔티티와 관계의 조합으로 정의됨
- 즉, \(\left\{{e_{t-k}},{r_{t-k+1}},\dots,{e_{t-1}},{r_{t}}\right\}\)
- k-step history는 과거 \(k\)단계의 모든 엔티티와 관계의 조합으로 정의됨
사용자 \(u\)에 의해 조건부로 초기 상태는 \(s_{0}=(u,u,\varnothing)\)로 표시 됨.
고정된 시간 \(T\)가 주어지면, terminal state는 \(s_{T}=(u,e_{T},h_{T})\)
action
- state \(s_t\)의 전체 액션 공간 \(A_t\)는 엔티티 \(e_t\)의 모든 가능한 outgoing edge로 정의 됨. 이는 history 엔티티와 관계를 제외함.
- 다음과 같이 표현할 수 있음. \(A_{t}\ =\ \{(r,e)\ \mid\ (e_{t},r,e)\ \in\ {\mathcal{G}}_{\mathrm{R}},e\ \not\in\ \ \{e_{0},\ldots,e_{t-1}\}\}\)
- out-degree 는 긴 꼬리 분포를 따르므로(대부분이 낮은 out-degree를 가지지만 소수의 노드들이 매우 높은 out-degree를 가짐), 일부 노드는 나머지 노드에 비해 훨씬 더 큰 out-degree를 가질 수 있음.
- 가장 큰 아웃 디그리에 따라 액션 공간의 크기를 유지하는 것은 공간 효율성이 매우 낮음
- -> 따라서, 사용자 조건부 액션 가지 치기 전략을 도입
- => 시작 user에 조건부로 유망한 엣지를 유지함. 구체적으로, scoring function \(f((r,e)\mid u)\)는 사용자 \(u\)에 조건부로 엣지 \((r,e)\) \((\forall r\in R,\forall e\in{\mathcal{E}})\)를 real-valued 스코어로 매핑함. 그런 다음, state \(s_t\)의 사용자 조건부 가지치기 액션 공간 \({\tilde{A}}_{t}(u)\)를 다음과 같이 정의함.
- $$\tilde{A}_{t}(u)=\{(r,e)\mid\mathrm{rank}(f((r,e)\mid u))\leq\alpha,(r,e)\in A_{t}\},\qquad(1)$$
- \(\textstyle{\mathcal{\alpha}}\) : 액션 공간의 크기를 상한하는 미리 정의된 정수
- scoring function \(f((r,e)\mid u)\) 은 다음 섹션에서 자세히 논의할 예정
reward
- 그 어떤 user라도, KGRE-Rec 문제에서 사전에 알려진 targeted item은 없다
- .그래서 user가 item과 상호작용하는지 여부를 나타내는 이진 reward를 고려하는 것은 불가능함
- 대신, agent는 가능한 많은 '좋은' 경로를 탐색하도록 권장됨. 추천의 맥락에서 '좋은' 경로는 사용자가 높은 확률로 상호작용할 항목으로 이어지는 경로임.
- 이를 위해, 우리는 terminal state \(s_{T}\,=\,(u,e_{T},h_{T})\)에 대해서만 또다른 scoring function \(f(u,i)\)을 기반으로 soft reward를 제공함. terminal reward \(R_T\)는 다음과 같이 정의됨.

여기서 \(R_T\)의 값은 [0,1]의 범위로 정규화 됨.
transition
그래프의 특성으로 인해 state는 엔티티의 위치에 따라 결정됨. 상태 \(s_{t}\,=\,(u,e_{t},h_{t})\)와 액션 \(a_{t}\,=(r_{t+1},e_{t+1})\)가 주어지면, 다음 상태 \(s_{t+1}\)로의 전이는 다음과 같음
$$\mathbb{P}\,\,[s_{t+1}=(u,e_{t+1},h_{t+1})|s_{t}=(u,e_{t},h_{t}),a_{t}=(r_{t+1},e_{t+1})]=1\ \ (3)$$
introduction에서 결정론적 MDP를 쓴다고 했는데, 그래서 전이 함수의 값이 1인것 같다
한가지 예외는 starting user 엔티티에 따라 결정되는 초기 state \(s_{0}\,=\,(u,u,\varnothing)\) 가 확률론적이라는 것. 단순화를 위해 우리는 user의 사전 분포(prior distribution)가 균일 분포를 따르며 각 사용자가 처음에 동일하게 샘플링된다고 가정함.
Optimization
우리의 MDP formulation에 따라, 우리의 목표는 초기 user \(u\)에 대해 기대 누적 reward를 최대화하는 확률적 정책 \(\pi\)를 학습하는 것임 :
$$J(\theta)=\mathbb{E}_{\pi}\left[\sum_{t=0}^{T-1}{\gamma^{t}}R_{t+1} | s_{0}=(u,u,\emptyset)\right] \quad\quad (4)$$
- 우리는 baseline [24] 를 사용하여 \(REINFORCE\)를 통해 문제를 해결함:
- 동일한 feature layer를 공유하는 policy 네트워크와 value 네트워크를 설계
- policy network \(\pi(\cdot|s,{\tilde{\bf A}}_{u})\)는 가지치기된 액션 공간 \({\tilde{A}}(u)\)의 상태 벡터 \(s\)와 이진화된 벡터 \({\tilde{\mathbf{A}}}_{u}\)(이진 벡터) 를 입력으로 받아 각각의 액션에 대한 확률을 출력함. 이때, \({\tilde{A}}(u)\) 에 없는 행동에 대한 확률은 0임.(가지치기 된 액션은 확률이 0임.)
- value network \({\hat{v}}(\mathbf{s})\)는 state 벡터 \(s\)를 real value로 매핑해서 \(REINFORCE\)의 baseline으로 사용됨.
- policy network와 value network의 구조는 다음과 같음.
- $${\bf x}=\mathrm{d}{\bf r o p o u t}(\sigma(\mathrm{d}{\bf r o p o u t}(\sigma(\mathrm{sW}_{1})){\bf W}_{2}))~~~~~~~~~(5)$$
$$\pi(\cdot|{\bf s},\tilde{\bf A}_{u})=\mathrm{softmax}(\tilde{\bf A}_{u}\odot({\bf x}W_{\mathrm{p}}))\qquad\qquad\qquad\qquad\qquad(6)$$
$$\hat{\upsilon}(s)={\bf x W_{v}} \quad\quad(7)$$- 여기서 \({\mathrm{x}}\in\mathbb{R}^{d_{f}}\) 는 state의 학습된 숨겨진 특징을 의미
- \(\odot\) : Hadamard product(아다마르 곱) (걍 element wise 곱 말하는거) => 무효한 액션을 마스킹하는 데 사용됨
- \(\sigma\) : 비선형 활성화 함수 (Exponential Linear Unit (ELU) 사용함)
- state 벡터 \(\mathbf{s}\in\mathbb{R}^{d_{S}}\) : 임베딩 \(u, e_t\)와 히스토리 \(h_t\)의 연결로 표현
- 이진화된 가지치기한 액션 공간 \({\tilde{\bf{A}}}_{u}\in\{0,1\}^{d_{A}}\)의 경우, 모든 가지치기된 액션 공간 중 최대 크기 \(d_A\)를 설정함.
- 두 네트워크의 모델 파라미터는 \(\Theta=\{{\bf W}_{1},{\bf W}_{2},{\bf W}_{{\bf p}},{\bf W}_{\bf v}\}\)로 나타냄.
- 또한, 에이전트가 더 다양한 경로를 탐색하도록 정책의 엔트로피를 최대화하는 정규화 항 \(H(\mathcal{\pi})\)를 추가함.
-
더보기엔트로피는 불확실성 또는 다양성을 나타내는 척도. 강화학습에서 정책의 엔트로피를 최대화한다는 것은 에이전트가 다양한 행동을 시도하도록 유도하는 것을 의미함. 높은 엔트로피는 에이전트가 특정 행동에만 치우치지 않고, 다양한 행동을 탐색하게 만들어줌.
-
- 마지막으로, 정책 gradient \(\nabla_{\Theta}J(\Theta)\)는 다음과 같이 정의됨:
- $$\nabla_{\Theta}J(\Theta)=\mathrm{\mathbb{E}}\!\pi\left[\nabla_{\Theta}\log\pi_{\Theta}(\cdot|s,\tilde{\bf A}_{u})\left(G-\hat{v}(s)\right)\right],\qquad\quad(8)$$
- 여기서 \({\boldsymbol{G}}\)는 state\(s\)에서 terminal state \(s_T\)까지의 할인된 누적 보상임.
- 식 (4)가 강화학습에서 최적화하고자 하는 목표 함수인 기대 보상 \(J(\theta)\)이고 에이전트는 이 기대보상을 최대화 하는 방향으로 학습을 진행함.
-
더보기정책 gradient (by hands on machine learning 3판)
: 정책 그래디언트(PG)알고리즘은 높은 보상을 얻는 방향의 그레디언트를 따르도록 정책의 파라미터를 최적화하는 알고리즘. -
더보기(8)은 손실함수를 최적화하기위한 정책 기울기를 계산하는 식임. 정책의 로그 확률에 보상의 차이를 곱한 형태.
정책 기울기 방법은 강화학습에서 정책 파라미터 \(\Theta\)를 최적화 하는 방법. 에이전트가 state \(s\)에서 특정 액션 \(a\)를 선택할 확률을 직접 학습함
$$\nabla_{\Theta}J(\Theta)=\mathrm{\mathbb{E}}\!\pi\left[\nabla_{\Theta}\log\pi_{\Theta}(\cdot|s,\tilde{\bf A}_{u})\left(G-\hat{v}(s)\right)\right],\qquad\quad(8)$$
상태 \(s\)에서 정책 \(\pi_{\Theta}\)가 액션을 선택할 확률의 로그에 대한 기울기를 구하고, 이를 보상 \(G\)와 상태 가치 함수 \({\hat{v}}(s)\)의 차이로 가중치를 준것임.
- 식 구성요소 설명
1. \(\mathbb{E}_\pi\) :
정책 \(pi\)에 따른 기대값을 의미. 즉, 정책 \(pi\)를 따르는 여러 에피소드의 평균을 계산하는 것
2. \(\nabla_{\Theta}\log\pi_{\Theta}(\cdot|s,\tilde{\bf A}_{u})\) :
상태 \(s\)에서 정책 \(\pi_{\Theta}\)에 따라 액션을 선택할 확률의 로그의 기울기를 계산한 것.
정책 \(\pi_{\Theta}\)는 파라미터 \(\Theta\)를 가진 함수. 주어진 상태에서 각 액션을 선택할 확률을 나타냄
3. \(G\) :
상태 \(s\)에서 시작해 terminal state에 도달할 때까지 얻는 총 누적 보상
식으로 나타내면 \(G=\sum_{t=0}^{T-1}\gamma^{t}R_{t+1}\)
여기서 \(\gamma\)는 할인율(discount factor). 미래의 보상을 현재 가치로 환산하는 데 사용됨.
(에이전트가 보상을 받았을 때, 어떤 행동 덕분인지(혹은 탓인지) 알기 어려움. 주인의 말을 잘 따르고 몇 시간이 지나서 보상을 받는 강아지의 경우를 생각해보면 이 강아지는 무엇 떄문에 보상을 받는지 이해할 수없을 것. 이 문제를 해결하기 위해 도입한게 \(\gamma\).)
\(R_{t+1}\)은 시간\(t+1\)에서 받은 보상
4. \({\hat{v}}(s)\):
상태 \(s\)의 가치를 나타내는 함수. 보통 기준선(baseline)으로 사용되어 보상의 분산을 줄이고 학습을 안정화함.
# \(G\)와 \({\hat{v}}(s)\)
상태 \(s\)에서 시작해 보상 \(R_t\)를 받을 떄, 누적 보상 \(G\)는 다음과 같이 계산됨.
- \(t\) = 0 에서 보상 \(R_1\)을 받음
- \(t\) = 1 에서 보상 \(R_2\)을 받음
- \(t\) = 2 에서 보상 \(R_3\)을 받음
누적 보상 \(G\)는 : \(G = R_1 + \gamma{R_2} + \gamma^{2}{R_3}\)
식 (8)은 정책 손실 함수를 최적화 하기 위한 기울기를 계산하는 식임. 보상 \(G\)는 할인된 누적 보상으로, 각 시간 단계에서 받은 보상을 할인율 \(\gamma\)로 조정한 합이다. 이를 통해 에이전트가 더 나은 정책을 학습하고, 최적의 경로를 탐색할 수 있음
상태 가치 함수 ({\hat{v}}(s)\)를 기준선으로 사용한다는 것의 의미 : 상태 가치 함수 \({\hat{v}}(s)\)를 이용해 보상의 분산을 줄이고 학습을 안정화 하는 것을 목표로 함.
이를 통해 정책 기울기 방법에서 계산된 기울기의 변동성을 줄이고 더 효율적으로 학습할 수 있음.
기준선(baseline)의 역할 : 기준선을 사용하는 주요 이유는 기울기 추정의 분산을 줄여 학습을 더 안정적이고 빠르게 만드는 것이다. 정책 gradient 방법에서 보상 \(G\)을 기준으로 기울기를 계산하는데 이때 baseline \({\hat{v}}(s)\)를 사용해 기울기를 조정하면, 보상의 분산을 줄일 수 있음. 이를 통해 학습이 더 안정화 되고 , 최적의 정책을 더 빨리 찾을 수 있음.
(보상 \(G\)는 강화학습에서 에이전트의 행동에 대한 평가인데 이 값은 시간 단계마다 크게 변동할 수 있음. 여기서 abseline \({\hat{v}}(s)\) 을 빼면, 보상의 변동성을 줄일 수 있음.)
# (8)식은 정책 파라미터 \(\Theta\)를 업데이트하기 위한 기울기 계산에 사용됨.
$$\Theta\leftarrow\Theta+\alpha\nabla_{\Theta}J(\Theta)$$
여기서 \(\alpha\)는 학습율(learning rate)
- $$\nabla_{\Theta}J(\Theta)=\mathrm{\mathbb{E}}\!\pi\left[\nabla_{\Theta}\log\pi_{\Theta}(\cdot|s,\tilde{\bf A}_{u})\left(G-\hat{v}(s)\right)\right],\qquad\quad(8)$$
- 동일한 feature layer를 공유하는 policy 네트워크와 value 네트워크를 설계
- 목표 함수 : 모델이 달성하려고 하는 최종 목표.(여기서는 누적 보상을 최대화하는게 목표 함수)
- 손실 함수 : 목표 함수를 최소화하기 위해 정의된 함수. 모델의 예측과 실제 값 간의 차이를 측정함
- 기울기 : 손실 함수 또는 목표 함수의 파라미터에 대한 변화율을 나타냄. 이 정보를 사용해 파라미터를 업데이트함
- 정책 gradient식에서는 \(G\)가 실제로 받은 할인된 누적 보상이고, \({\hat{v}}(\mathbf{s})\)는 예상 보상으로, 이 차이를 통해 에이전트가 자신의 정책을 어떻게 개선할지 학습함.
3.3 Multi-Hop Scoring Function
이제 우리는 행동 가지치기 전략과 보상 함수에 대한 scoring function을 제시함.관련 개념부터 시작하면,,
- \(\mathcal{G}_{\mathrm{{R}}}\) 의 한 가지 특성은 head entitiy의 type과 타당한 realtion가 주어지면, tail entity의 type도 결정된다는 것. 이 특성을 확장하여 엔티티와 relation types의 chain rule을 만들 수 있음 : \(\{e_{0},r_{1},e_{1},r_{2},\cdot\cdot\cdot,r_{k},e_{k}\}\)
- 엔티티 \(e_0\)와 모든 관계 \(r_{1},\cdot\cdot\cdot,r_{k}\)의 types이 주어지면, 나머지 엔티티 \(e_{1},\ldots,e_{k}\)의 types은 unique하게 결정됨. 이 규칙에 따라 다음과 같은 patterns의 개념을 도입함.
Definition 3.3 (k- hop pattern)
- 두 엔티티 \((e_{0},e_{k})\)에 대해 \(k\)관계의 시퀀스\({\tilde{r}}_{k}=\{r_{1},\ldots,r_{k}\}\)가 유효한 k-hop 패턴이라고 불리기 위해서는...,
- types이 고유하게 결정되는 엔티티 집합 \(\{e_{1},\ldots,e_{k-1}\}\)이 있어야 하며,
- \(\left\{e_{0}\stackrel{r_{1}}{\longleftrightarrow}e_{1}\stackrel{r_{2}}{\longleftrightarrow}\cdot\cdot\cdot\stackrel{r_{k}}{\longleftrightarrow}e_{k}\right\}\) 이 \(\mathcal{G}_{\mathrm{{R}}}\)에서 유효한 k-hop 경로를 형성해야 함.
- 패턴에 대한 주의사항 중 하나는 경로에서 역방향 엣지를 허용하는 경우 각 relation의 방향입니다.
- 엔티티 \(e,e^{\prime}\)와 관계 \(r\)의 경우, \(e\stackrel{r}{\longleftrightarrow}e^{\prime}\) 는 경로에서 \(e\stackrel{r}{\longrightarrow}e^{\prime}\) 또는 \(e\stackrel{r}{\longleftarrow}e^{\prime}\) 를 나타냄.
- 관계 \(r\)의 경 \((e,r,e^{\prime})\in {\mathcal{G}}_R\) 이고 \(e\stackrel{r}{\longrightarrow}e^{\prime}\) 인 경우 정방향(forward)으로, \((e^{\prime},r,e)\in{\mathcal{G}}_R\)이고 \(e\stackrel{r}{\longleftarrow}e^{\prime}\) 인 경우 역방향(backward)으로 간주함.
- 행동 가지치기 과 reward에 대한 scoring function를 정의하기 위해 정방향 및 역방향 관계가 모두 포함된 패턴의 특별한 경우를 고려함.
Definition 3.4 (1-reverse k-hop pattern)
- k-hop 패턴은 \(1-reverse\)임
- 표시는 이렇게 : \(\tilde{r}_{k,j}\,=\,\{r_{1},\ldots\cdot,r_{j},r_{j+1},\ldots\cdot,r_{k}\}\,\,(j\in[0,k])\)
- \(r_{1},\cdot\cdot\cdot,r_{j}\) 는 정방향, \(r_{j+1}\cdot\cdot\cdot r_{k}\)는 역방향.
- 즉, \(1-reverse k\)-hop 패턴을 가진 경로는 \(e_0 \stackrel{r_1}{\longrightarrow}\cdot\cdot\cdot\stackrel{r_j}{\longrightarrow}e_j\stackrel{r_{j+1}}{\longleftarrow}e_{j+1}\stackrel{r_{j+2}}{\longleftarrow}\cdot\cdot\cdot\stackrel{r_k}{\longleftarrow}e_{k} \) 의 형태를 가짐.
- \(j = 0\)인 경우 패턴은 모든 역방향 관계를 포함하며, \(j = k\)인 경우 모든 정방향 관계를 포함함.
- 표시는 이렇게 : \(\tilde{r}_{k,j}\,=\,\{r_{1},\ldots\cdot,r_{j},r_{j+1},\ldots\cdot,r_{k}\}\,\,(j\in[0,k])\)
이제 주어진 \(1-reverse\) k-hop 패턴 \({\tilde{r}}_{k,j}\)에 대해 두 엔티티 \(e_0,e_k\)의 일반적인 다중 홉 scoring function \(f(e_0,e_k | {\tilde{r}}_{k,j})\)를 다음과 같이 정의함.
$$f(e_{0},e_{k}\mid\widetilde{r}_{k,j})=\left<\mathrm{e_{0}}+\sum_{s=1}^{j}\mathrm{r}_{s},\ \mathrm{e_{k}}+\sum_{s=j+1}^{k}\mathrm{r}_{s}\right>+b_{e_{k}},\qquad(9)$$
- 여기서 \(\langle\cdot,\cdot\rangle\) : 내적 연산을 의미
- \(\mathrm{e,r}\in\mathbb{R}^{d}\) : 엔티티 \(e\)와 realtion \(r\)의 d-차원 벡터 표현
- \(b_{e}\in\mathbb{R}\) : 엔티티 \(e\)의 bias
더보기정방향 경로랑 역방향 경로 내적구해서 2개 유사도를 점수 함수로 쓰는 관점이 처음에 이해가 안갔는데 TransR에서 (h,r,t)가 있을 때 h+r = t 가 되는 관점에서 보는 것과 유사한 느낌이라고 생각이 듦.
- \(k = 0, j = 0\)인 경우, scoring function은 단순히 두 벡터 간의 코사인 유사도를 계산함.
- $$f(e_{0},e_{k}\mid\tilde{r}_{0,0})=\langle\mathrm{e}_{0},\mathrm{e}_{\bf k}\rangle+b e_{k}\,.\qquad\qquad\qquad(10)$$
- \(k = 1, j = 1\)인 경우, scoring function은 두 엔티티 간의 유사도를 translational embeddings[2]를 통해 계산함.
- $$f(e_{0},e_{k}\mid\tilde{{{r}}}_{1,1})=\langle\mathrm{e}_{0}+\mathrm{r}_{1},\;\mathrm{e}_{\mathrm{k}}\rangle+b e_{k}\qquad\qquad\qquad(11)$$
- \(k\geq1,1\leq j\leq k\)인 경우, \(1-reverse k\)-hop 패턴을 기반으로 방정식 (9)의 scoring function를 이용해 두 엔티티 간의 유사도를 정량화 함.
Scoring Function for Action Pruning
사용자 엔티티 \(u\)와 다른 유형의 엔티티 \(e\)에 대해, 어떤 정수 \(k\)에 대해 하나의 \(1-reverse\) k-hop 패턴 \(
{\tilde{r}}_{k,j}\)만 있다고 가정했을 때,
엔티티 \(e\not\in{\mathcal{U}}\)인 경우, 엔티티 \((u,e)\)에 대해 \({\tilde{r}}_{k,j}\)가 유효한 패턴인 가장 작은 \(k\)를 \(k_e\)로 나타냄. 따라서, 행동 가지치기를 위한 scoring function은 \(f((r,e)\mid u)=f(u,e\mid{\tilde{r}}_{k_{e},j})\)로 정의됨.
뇌피셜 끄적 끄적
action pruning을 위한 점수함수는 \(f((r,e)\mid u)\)로 정의되는데, 이는 \(u\)와 \(e\)간의 1-reverse k-hop 패턴 \({\tilde{r}}_{k,j}\)을 기반으로 하므로 action pruning에서 scoring function은 \(f(\,u,e|{\tilde{r}}_{k_e},j)\)로 정의되는듯
이렇게 해서 저 scoring 함수를 사용하면 특정 엔티티에서 중요도가 높은 관계는 더 높은 점수를 받고, 중요도가 낮은 관계는 더 낮은 점수를 받게 되는 원리인 듯 하다.(결국 중요도가 낮은 out-degree값이 자연스럽게 낮아지고 중요도가 높은 값은 높아지는 결과를 낳게 되는 듯)
앞에서 \({\tilde{\bf A}}_{u}\) 사용자 u와 다른 엔티티 간의 관계를 나타내는 행렬이라고 했으니까 저 scoring 함수 결과로 채워지는 거 아닐까?앞에서 \({\tilde{\bf A}}_{u}\)는 이진 벡터라고 했으니까,scoring function으로 계산된 점수를 기반으로 점수가 일정 수준 이상으면 1, 아니면 0으로 해서 \({\tilde{\bf A}}_{u}\)가 되는 그런 느낌.이때 0이 가지치기 된 경로인거고,
특정 state에서 다음 엔티티로 넘어갈건데 이때 가능한 action 집합이 있을테고(relation,entity pair 집합)이거에 대해서 scoring fuction을 다 계산했을 때 그 점수가 높은걸 살리고 아니면 버리는 방식인듯
생각보니까 시작 user가 주어졌을 때, 현재 state에서 새로 연결될 relation과 entity에 대해 scoring function을 계산하는(\(f((r,e)\mid u)\)) 이게 1-reverse k-hop pattern이 주어졌을 때, 시작 user u에서 엔티티 e까지 점수를 계산한거니까, 즉 u랑 e 유사도를 계산한거니까(새로 주어진 relation과 entity 이전의 경로는 \( {\tilde{r}}_{k_{e},j} \)이 패턴 그대로 계속 쓰는 것 같음. 그래서 새로 얹어질 경로 r과 엔티티 e에 대한 점수 계산이 되는거고, 그 점수 비교해서 높은 거 몇개만 살리고 나머지는 가지치기 하는 과정인듯
Scoring Function for Reward
우리는 단순하게 user 엔티티와 item 엔티티 간의 1-hop 패턴을 사용함.(즉, \((u,r_{u i},i)\in{\mathcal{G}}_{\mathrm{R}}\))
reward 설계를 위한 scoring 함수는 \(f(u,i)=f(u,i|{\tilde{r}}_{1,1}).\)로 정의됨.
- 저기서 \(u\)는 사용자 엔티티
- \(i\)는 item 엔티티
- \(\tilde{r}_{1,1}\)는 1-hop 패턴을 의미함.
끄적 끄적 뇌피셜
전체 경로가 k인데 왜 보상을 위한 score 함수는 1-hop만 고려하는거임? 이라고 멍청하게 생각할 수 있지만 좀 생각해보니 이런 것 같음
-> 1-hop 패턴을 써서 사용자가 특정 아이템에 대해 취한 직접적인 행동(ex. 클릭, 구매)등을 평가하는 데 집중하는거임. 이런 직접적인 행동을 반영해서 reward 점수를 계산하는데 사용되는거 아닐까 하는...
이제 저기 scroring function for reward에서 \(i\)는 최종적으로 추천하는 아이템. 보상 함수는 사용자가 추천된 아이템에 대해 취한 행동을 평가하여 모델의 성능을 최적화하는 그런 느낌인듯.
Learning Scoring Function
여기서 자연스럽게 제기되는 질문은 각 엔티티와 relation에 대한 임베딩을 어떻게 학습할 것인가임.
valid k-hop 패턴 \({\tilde{r}}_{k,j}\)을 가진 엔티티 쌍 \((e,e')\)에 대해, 우리는 다음과 같은 조건부 확률을 최대화 하려고 함.:
$$\mathrm{P}(e^{\prime}\mid e,\tilde{r}_{k,j})=\frac{\exp\left(f(e,e^{\prime}\mid\tilde{r}_{k,j})\right)}{\sum_{e^{\prime\prime}\in{\cal E}}\exp\left(f(e,e^{\prime\prime}\mid\tilde{r}_{k,j})\right)}.\qquad\qquad(12)$$
뇌피셜 끄적 끄적
방정식(12)를 최대화한다는 것의 의미:
(12)의 조건부 확률은 주어진 엔티티 \(e\)와 경로 \({\tilde{r}}_{k,j}\)를 통해 도달할 엔티티 \(e'\)의 확률을 의미.
저 식에서 분자 : 특정 엔티티 \(e\)와 \(e'\)간의 유사성을 점수 함수로 계산
저 식에서 분모 : 모든 가능한 엔티티 \(e''\)에 대한 점수를 합한 값.
=> 조건부 확률을 최대화 한다는 것은 모델이 주어진 \(e\)와 경로 \({\tilde{r}}_{k,j}\)를 통해 \(e'\)로 도달하는 관계를 가장 잘 예측할 수 있도록 학습하는 것. -> 도달할 가능성이 높은 엔티티 \(e'\)을 더 높은 점수로 평가.
그렇게 해서 저 조건부 확률을 이용해 목적함수를 만들고 그걸 기반으로 scoring function을 학습하는거지. 여기서 업데이트 되는 대상은 엔티티와 relation 임베딩 값인거고.
위에 (4)번식은 강화학습 관점에서 장기적인 보상을 최대화 하는 목적함수인거고, (12)번 식은 scoring function을 학습하는데 쓰이는 목적함수인거고 엔티티와 관계의 임베딩을 잘 하기 위해 임베딩을 업데이트하기위한 목적함수인듯. 임베딩을 잘 해야 스코어링 함수로 더 정확한 유사도 계산도 가능한거니
그러나 엔티티 집합 \(\cal E\)크기가 매우 커서, 우리는 여기서 [17](skip-gram)의 negative sampling 기법을 채택해서
\(\log\mathrm{P}(e^{\prime}\mid e,{\tilde{r}}_{k,j})\)를 근사함 :
$$\log\mathrm{P}(e^{\prime}|e,\tilde{r}_{k,j})\approx\log\sigma\left(f(e,e^{\prime}\mid\tilde{r}_{k,j})\right)+\;m\mathbb{E}_{e^{\prime\prime}}\left[\log\sigma\left(-f(e,e^{\prime\prime}\mid{\tilde{r}}_{k,j})\right)\right]\qquad\qquad(13)$$

목표는 다음과 같이 정의된 목적 함수 \(J({\mathcal{G}}_{\mathrm{R}})\)를 최대화 하는 것. :
$$J({\mathcal G}_{\mathrm{R}})=\sum_{e,e^{\prime}\in{\mathcal E}}\sum_{k=1}^{K}\operatorname{I}\{(e,{\tilde{r}}_{k,j},e^{\prime})\}\log\operatorname{P}(e^{\prime}|e,{\tilde{r}}_{k,j}),\qquad(14)$$
여기서 \(\operatorname{I}\left\{(e,{\tilde{r}}_{k,j},e^{\prime})\right\}\)은 \({\tilde{r}}_{k,j}\)가 엔티티 \((e,e^{\prime})\)에 대해 유효한 패턴인 경우 1, 그렇지 않은 경우 0.
그래서 결론적으로 계산량을 줄인 근사식 log P 를 이용해서 scoring 함수의 목적함수가 방정식 (14)로 정의한거지 응 그렇게 이해함.
\(\log\mathrm{P}(e^{\prime}\mid e,{\tilde{r}}_{k,j})\) 는 엔티티 \(e\) 와 경로 \({\tilde{r}}_{k,j}\)가 주어졌을 때, 엔티티 \(e^{\prime}\)에 도달할 확률의 로그 값이 되는거니까,
그래서 결론은 저 목적함수 \(J({\mathcal{G}}_{\mathrm{{R}}})\)을 사용해서 손실함수 계산하고, 최적의 임베딩 벡터를 학습하도록 하는 듯.
위에서 말한 negative sampling 에서 negative sample에 해당하는 \(e''\)은 주어진 엔티티 \(e\)와 연결되지 않은 일부 샘플을 말하는 것 같음.
3.4 Policy-Guided Path Reasoning
최종 단계는 훈련된 policy network를 사용해서 지식 그래프 상에서 추천 문제를 해결하는 것임.
사용자 \(u\)가 주어졌을 때 목표는 후보 아이템 집합 \(\scriptstyle\{i_{n}\}\)과 이에 해당하는 reasoning path \(\{p_{n}(u,i_{n})\}\)를 찾는 것임.
간단한 방법은 정책 네트워크 \(\pi(\cdot|{\bf s},\tilde{\bf A}_{u})\)에 따라 각 사용자 \(u\)에 대해 n개의 경로를 샘플링 하는 것. 그러나 이 방법은 정책 네트워크에 의해 안내되는 agent가 가장 큰 누적 보상을 가진 동일한 경로를 반복적으로 검색할 가능성이 높아서 경로의 다양성을 보장할 수 없음.
- 따라서 우리는 action probability 와 reward에 의해 안내 되는 beam search를 사용해 각 사용자에 대한 후보 경로와 추천 아이템을 탐색할 것을 제안함.
-
더보기beam search 참고글
https://deepdata.tistory.com/273#google_vignette - 해당 과정은 Algorithm 1에 설명됨.
-

- input :
사용자 \(u\),정책 네트워크 \(\pi(\cdot|{\bf s},\tilde{\bf A}_{u})\), horizon \(T\), 각 단계에서 사전 정의된 샘플링 크기 \(K_{1},\cdot\cdot\cdot,K_{T}\) - output :
user에 대한 \(T\)-hop 경로 후보 집합 \(\mathcal{P}_{T}\), 이에 상응하는 경로 생성 확률 \({\boldsymbol{Q_{T}}}\) 및 경로 보상 \({\mathcal{R}}_{T}\). - 각 경로 \(p_{T}(u,i_{n})\in\mathcal{P}_{T}\)는 경로 생성 확률 및 경로 보상과 연관된 item 엔티티로 끝남.
- 획득된 후보 경로의 경우, 사용자 \(u\)와 아이템 \(i_n\)사이에 여러 가지 경로가 존재할 수 있음.
- 따라서 후보 집합의 각 \((u,i_n)\)쌍에 대해, 우리는 \(Q_{T}\)를 기반으로 가장 높은 생성 확률을 가진 경로를 선택해 item \(i_n\)이 사용자 \(u\)에게 추천되는 이유를 해석함.
- 마지막으로, 우리는 \(R_T\)의 경로 보상에 따라 선택된 해석 가능한 경로를 순위 매기고 해당 아이템을 사용자에게 추천함.
4 EXPERIMENTS
이 섹션에서는 실제 데이터 셋을 사용해 우리의 PGPR 방법의 성능을 평가함. 먼저 실험에 사용된 벤치마크와 해당 실험 설정을 소개함. 그런 다음 우리의 모델을 최신 접근 방식들과 정량적으로 비교하고, 파라미터 변화가 모델에 어떤 영향을 미치는지 보여주는 제거 연구(ablation studies)를 수행
4.1 Data Description
- 모든 실험은 Amazon 전자 상거래 데이터셋 컬랙션에서 수행. 여기에는 Amazon.com의 제품 리뷰와 메타 정보가 포함되어 있음.
- 4가지 카테고리로 구성 : CDs and Vinyl(레코드판 같은), Clothing, Cell Phones ,Beauty
- 각 카테고리는 지식 그래프를 구성하고, 5가지 유형의 엔티티와 7가지 유형의 relations를 포함함
(Table 1 : entities와 realtions의 설명 및 통계)
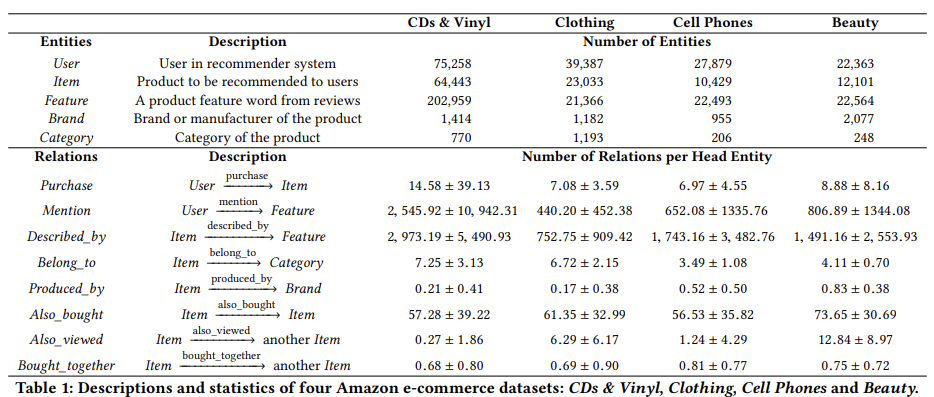
- 헤드 엔터티와 관계 type이 제공되면 테일 엔터티의 type은 고유하게 결정됨.
- train test data split은 사용자의 purchases 중 70%를 훈련 데이터로 무작위로 샘플링하고 나머지 30%를 테스트 데이터로 사용.
- KGRE-Rec 문제의 목표 : 테스트 세트에서 사용자가 구매한 item을 추천하고 각 user-item 쌍에 대한 추론 경로를 제공하는 것.
4.2 Experimental Setup
Baselines & Metrics
- 우리의 결과를 이전의 최신 방법들과 비교함.
- BPR(Bayesian personalized ranking model)[20] : 사용자의 latent 임베딩을 학습하는 베이지안 ranking model
- BPR-HFT [16] : 리뷰에서 latent factors를 학습하기 위해 topic disribution를 통합한 Hidden Factors and Topics(HFT) 모델
- VBPR[8] : BPR 모델을 기반으로 하면서 시각적 제품 knowledge를 통합하는 Visual Bayesian Personalized Ranking 방법
- TransRec[6] :순차적 추천을 위한 번역 기반 임베딩을 사용함. 개인화된 translation vectors를 통해 사용자와 item표현을 공유 임베딩 공간에 매핑하는 방법을 학습함.
-
더보기뇌피셜 끄적 끄적
순차적 추천이라는게 사용자의 history데이터를 기반으로 다음 아이템을 예측한다는 의미인 것 같다
TransRec은 사용자와 아이템 간의 상호작용을 기반으로 순차적 추천을 수행하는데, 사용자 u와 아이템 i와 j간의 관계를 모델링 해서 사용자가 아이템 i를 소비한 후 다음 아이템으로 j를 소비할 확률을 예측함. 이때 아이템은 임베딩 벡터로, 사용자는 번역 벡터로 표현 하는듯.
번역 기반 임베딩이라는게 번역 벡터를 만든다는 것 같은데, 번역 벡터는 사용자의 행동 패턴을 모델링하는 데 사용되는 것 같음. 사용자가 특정 아이템을 본 후 다음 아이템을 선택할 때 특정한 경향이 이런 경향을 번역 벡터가 나타내주는 것 같다. 즉, 사용자와 다음 아이템, 다다음 아이템간의 관계를 모델링.
임베딩 벡터는 무엇인가 : 임베딩 벡터는 아이템의 특성을 수치화해서 벡터 형태로 표현한 것으로 예를 들어 영화의 장르, 배우, 감독 등의 특징을 하나의 벡터로 표현한 것. 이 벡터는 벡터 공간에서 아이템 간의 유사성을 나타내는데 사용됨.
아이템 임베딩 학습하고, -> 번역 벡터 학습하고, -> 목표 함수 최적화 하고,(이떄 BPR 손실 함수를 사용해서 모댈의 목표 함수를 최적화 하는 듯) 이렇게 해서 사용자의 히스토리 데이터를 기반으로 다음에 소비할 아이템을 예측하는 모댈.
즉, 사용자 번역 벡터와 아이템 입베딩 벡터를 결함해 사용자가 특정 아이템을 소비할 확률을 계산함.
-
- DeepCoNN( Deep Cooperative Neural Networks ) [36]: rating prediction에 도움이 되는 리뷰를 사용하여 user와 item을 모두 인코딩하는 방법을 학습하는 리뷰 기반 컨볼루션 추천 모델.
-
더보기
DeepCoNN 모델 리뷰
DeepCoNN (Deep Cooperative Neural Networks)은 리뷰 텍스트를 활용하여 사용자와 아이템의 속성을 공동으로 학습하는 추천 시스템 모델입니다. 이 모델은 사용자 리뷰와 아이템 리뷰를 활용하여 사용자의 행동과 아이템의 특성을 학습하고, 이를 바탕으로 추천을 수행합니다. DeepCoNN은 두 개의 병렬 신경망으로 구성되며, 마지막 레이어에서 결합되어 사용자와 아이템의 숨겨진 요인(latent factors)을 상호작용시킵니다.
주요 구성 요소 및 학습 과정:
- 리뷰 텍스트 표현:
- 단어 임베딩: 리뷰 텍스트는 단어 임베딩 매트릭스로 변환되어 리뷰 텍스트의 의미 정보를 캡처합니다. 모든 사용자 리뷰는 하나의 문서로 병합되어 단어 임베딩 매트릭스를 생성합니다.
- CNN 레이어: 단어 임베딩 매트릭스는 합성곱 신경망(CNN)의 입력으로 사용됩니다. CNN 레이어는 단어 벡터에 대해 합성곱 연산을 수행하여 새로운 특징을 생성합니다. 이 과정에서 맥스 풀링(max pooling)을 통해 중요한 특징을 추출합니다.
- 사용자 및 아이템 네트워크:
- 병렬 신경망: 사용자와 아이템에 대해 각각 별도의 신경망이 존재하며, 마지막 레이어에서 결합됩니다. 각 신경망은 사용자 또는 아이템 리뷰를 입력으로 받아, 이를 통해 특징을 학습합니다.
- 완전 연결 레이어: 맥스 풀링 레이어의 출력은 완전 연결 레이어로 전달되어 사용자의 특징을 학습합니다.
- 공유 레이어:
- 특징 결합: 사용자와 아이템의 특징을 결합하여 동일한 특징 공간으로 매핑합니다. 이를 통해 두 특징 벡터 간의 상호작용을 모델링합니다.
- 평점 예측: 공유 레이어에서 Factorization Machine(FM)을 사용하여 예측 평점을 계산합니다.
- 학습 및 최적화:
- RMSprop: RMSprop 알고리즘을 사용하여 네트워크를 최적화합니다. 이는 각 가중치의 업데이트 값을 해당 그레이디언트의 절대값의 이동 평균으로 스케일링하여 학습 속도를 조절합니다.
- 드롭아웃: 과적합을 방지하기 위해 드롭아웃 기법을 적용합니다.
성능 및 실험 결과:
DeepCoNN은 다양한 데이터셋에서 기존의 최첨단 추천 시스템과 비교하여 우수한 성능을 보였습니다. Yelp, Amazon, Beer 데이터셋을 사용하여 모델의 효율성을 평가한 결과, DeepCoNN은 리뷰 텍스트를 효과적으로 활용하여 추천 정확도를 높이는 데 성공했습니다.
- 리뷰 텍스트 표현:
-
- CKE( Collaborative Knowledge base Embedding [31] ) : top-N 추천 결과를 추론하기 위해 텍스트 콘텐츠, 시각적 정보 및 structure knowledge base를 포함하는 heterogeneous data 형식과 matrix factorization을 통합하는 joint model을 기반으로 하는 modern nerual recommender system
-
더보기CKE모델은 협업 필터링(CF)과 지식 그래프 임베딩을 결합해 추천 시스템 성능을 향상시키는 접근 방식.이 모델은 구조적 지식, 텍스트 정보, 시각적 정보를 통합해 아이템의 다양한 특성을 학습함. 이를 통해 사용자와 아이템 간의 더 깊은 관계를 모델링하고, 더 정확한 추천을 제공.
-
- JRL[32] : 이미지, 텍스트 및 평점을 포함한 멀티 모달 정보를 신경망에 통합한 state-of-the-art joint representation learning model.
-
더보기JRL 모델은 여러 모달리티(평점, 리뷰, 이미지 등)의 데이터를 통합해 사용자와 아이템의 특징을 학습하는 추천 시스템. 딥 뉴럴 네트워크를 사용하여 이런 다양한 정보 소스를 통해 사용자와 아이템의 잠재 표현을 학습하고, 이를 바탕으로 top-N 추천을 수행.
각 모달리티별로 별도의 딥 러닝 아키텍처를 사용해서 특징을 추출함. 예를 들어 리뷰 텍스트는 텍스트 임베딩 모델을 사용하고, 이미지는 이미지 임베딩 모델을 사용해 특징 추출
추출된 특징은 최종 사용자와 아이템의 통합 표현을 형성하는데 사용-> 사용자의 선호도 더 정확히 반영 가능
이를 바탕으로 특정 사용자가 특정 아이템을 선호할 가능성을 예측함. 이는 CF와 결합하여 더 정확한 추천을 제공. 예를 들어, 내적 또는 신경망 기반의 예측 모델을 사용할 수 있
-
- 우리는 대규모 데이터셋 때문에 user-item 쌍 간의 모든 가능한 경로를 열거할 수 없어서 KPRN 모델은 baseline에 포함하지 않음
- 모든 모델은 4가지 대표적인 top-N 추천 지표로 평가됨.(순위 지표는 테스트 세트의 각 user에 대한 상위 10개의 예측을 기반으로 계산)
- Normalized Discounted Cumulative Gain (NDCG)
- Recall
- Hit Ratio (HR)
- Precision (Prec)
-
더보기NDCG : 추천 item의 순위와 관련성을 평가하는 메트릭.
Recall : 실제 관련 item 중 올바르게 추천된 item의 비율
Hit Rate : 사용자가 실제로 선택한 item이 추천 목록에 포함되는 비율
Precision : 추천된 item 중 실제 관련 item의 비
- Implementation Details(구현 디테일).
- 모든 실험에 대한 기본 파라미터 설정은 다음과 같음
- KGRE-Rec 문제의 경우, maximum path length를 3으로 설정함.
- 추천 이유를 해석 하는 것에 있어서 사용자의 입장에서는 짧은 경로가 더 신뢰할 수 있다고 가정함
- medel의 latent representations를 위해 모든 엠티티와 관계의 임베딩은 1-hop scoring function(11번 식)을 기반으로 학습되며, 임베딩 크기는 100으로 설정함.
- $$f(e_{0},e_{k}\mid\tilde{{{r}}}_{1,1})=\langle\mathrm{e}_{0}+\mathrm{r}_{1},\;\mathrm{e}_{\mathrm{k}}\rangle+b e_{k}\qquad\qquad\qquad(11)$$
- 강화학습 측면에서,
- history vector \(h_t\)는 \(e_{t-1}\)과 \(r_t\)의 임베딩을 연결하여 표현됨
- => 상태 벡터 \(\mathbf{st}=(\mathbf{u},\mathbf{e_{t}},\mathbf{e_{t-1}},\mathbf{r_{t}})\) 의 크기는 400
- pruned action space의 최대 크기는 250으로 설정. 즉, 어떤 state에서도 최대 250개의 액션이 있음
- 경로의 다양성을 촉진하기 위해 pruned action space에 대해 0.5의 비율로 action dropout 적용함.
- discount factor \(\gamma\)는 0.99로 설정.
- policy/ value network의 경우,\(W_{1}\in\mathbb{R}^{400\times512},\,W_{2}\in\mathbb{R}^{512\times256},\,W_{p}\in\mathbb{R}^{256\times250},W_{v}\in\mathbb{R}^{256\times1}\)
- history vector \(h_t\)는 \(e_{t-1}\)과 \(r_t\)의 임베딩을 연결하여 표현됨
- 모든 4가지 데이터 셋에 대해, 우리의 모델은
- Adam 최적화 사용해서 50 에포크 동안 학습됨.
- CDs & Vinyl 데이터 셋에 대해 : learning rate 0.001, batch size 64로 설정
- 다른 데이터 셋에 대해서는 learning rate 0.0001, batch size 32로 설정
- enrtophy loss의 가중치는 0.001 (이게 앞에서 언급했던 정규화 항 \(H(\pi)\)인 것 같음)
- 경로 추론 단계에서 각 단계의 샘플링 크기는 (이게 beam search할떄 쓰이는 것 같다)
- CDs & Vinyl 의 경우 \(K_1 = 20, K_2 = 10, K_3 = 1\)
- 나머지 3개의 데이터 셋에 대해서는 \(K_1 = 25, K_2 = 5, K_3 = 1\)
- KGRE-Rec 문제의 경우, maximum path length를 3으로 설정함.
- 모든 실험에 대한 기본 파라미터 설정은 다음과 같음
4.3 Quantitative Analysis
실험의 경과는 Table2에 있음.

- 우리가 제안한 PGPR 방법이 모든 데이터 셋에서 NDCG, Hit Rate, Recall 및 Precision 측면에서 다른 모든 베이스라인보다 일관되게 우수한 성능을 보임.
- 예를 들어, CD 및 바이닐 데이터셋에서 최고 베이스라인(JRL)보다 3.94%의 NDCG 향상을, 의류에서는 64.73%, 휴대폰에서는 15.53%, 뷰티에서는 23.95%의 상당한 향상을 보임. 모든 데이터 셋에서도 유사항 경향 관찰 가능.\
- 이는 지식 그래프에서 추론 경로를 탐색하는 것이 item 추천에 상당한 이점을 제공하므, 해석 가능성 문제가 없더라도 그래프를 통한 추천에 유망한 기술임을 알 수 있음.
- 우리의 경로 추론 프로세스는 KG에서 rich한 heterogeneous imformation을 통합하고 엔티티 간의 multi-hop 상호 작용을 캡쳐하는 학습된 정책 네트워크에 의해 guide됨.
- e.g., \(User\, Mentions\, Feature, Feature\, is \,Described \,by \,Item, Time \,Belongs \,to \,Category\), etc
- 그리고 이는 우리의 방법의 유망한 추천 성능에 크게 기여함.
- TransE(KG embedding하는 방법 중 하나임) 를 추천에 직접 적용하는 것이 우리보다 약간 더 우수함
- 이 방식은 single-hop latent matching method로 간주 될 수 있지만, 사후 설명은 추천 생성의 실제 이유를 방드시 반영하지 않음.
- 반면, 우리 방법은 KG를 통한 명시적 경로 추론 과정을 통해 추천을 생성함 -> 설명이 directly하게 decisions이 어떻게 생성되었는지 반영해줌(이게 시스템을 투명하게 만들어줌)
- valid reasoning path을 찾는데 있어서 우리 방법의 효율성을 조사함.
- 경로가 valid하다고 간주되려면, user로부터 시작해 3개의 hop이내에 item 엔티티에서 끝나야 함. (즉, 경로에 최대 4개의 엔티티 존재 가능)
- Table 3에 표시된 바와 같이 우리는 각각 user 당 평균 valid path의 수, user당 평균 unique item수 및 item당 평균 supportive한 path수를 적어둠.
- 두가지 흥미로운 사실을 발견했는데,
- 우리의 방법이 valid한 경로를 찾는 성공률은 약 50%로 , CD &Vinyl데이터 셋의 경우 200개의 경로, 다른 경우 125개의 경로에서 valid 한 경로 수로 계산 됨. 특히 휴대폰 데이터 셋의 경우 거의 모든 경로가 valid함. 각 user에서 item으로의 가능한 모든 경로 수가 매우 많고 우리의 추천 문제의 난이도가 높은 점을 고려했을 때, 이런 결과는 경로 찾기 속성 측면에서 우리의 방법이 매우 잘 수행됨을 알 수 있음.
- 각 추천 항목은 약 1.6개의 추론 경로와 관련이 있음. 이는 각 추천에 대해 뒷받침되는 증거로 사용할 수 있는 추론 경로가 있음을 의미함. 따라서 사용자가 추가 세부 정보를 요청하는 경우 이런 경로 중 하나 이상을 제공하는 것을 고려할 수 있음
4.4 Influence of Action Pruning Strategy
이번 실험에서는 pruned action spaces의 크기에 따라 모델의 성능이 어떻게 달라지는지 평가함.
starting user을 기준으로 액션 공간은 식(9)에 정의된 scoring function에 따라 가지치기 되며, 점수가 큰 액션이 보존될 가능성이 더 높음.
$$f(e_{0},e_{k}\mid\widetilde{r}_{k,j})=\left<\mathrm{e_{0}}+\sum_{s=1}^{j}\mathrm{r}_{s},\ \mathrm{e_{k}}+\sum_{s=j+1}^{k}\mathrm{r}_{s}\right>+b_{e_{k}},\qquad(9)$$
즉, 더 큰 액션 공간에는 사용자와 덜 관련된 액션이 더 많이 포함됨. 이 실험은 더 큰 액션 공간이 potential items을 찾기 위해 더 많은 추론 경로를 탐색하는데 도움이 되는지 보여줌.
- 우리는 Clothing과 Beauty라는 2개의 데이터셋을 선택해서 실험을 수행함.
- 이전 섹션의 기본 설정을 유지하되 가지치기된 액션 공간의 크기를 100에서 500까지 50 단위로 변경함.
- 실험의 결과는 Figure 3과 Figure 4에 표시됨.
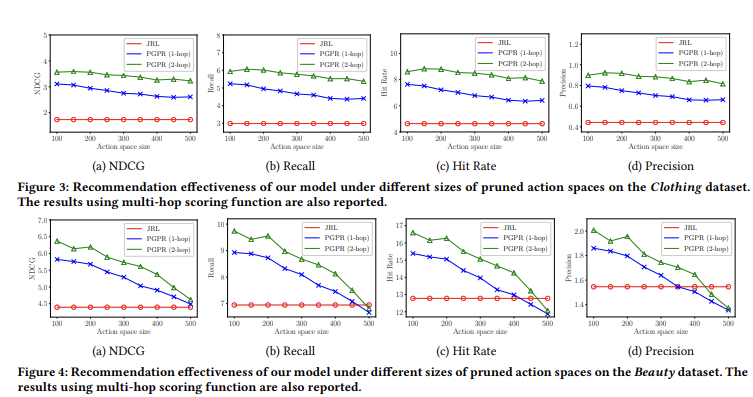
- 비교를 위해 PGPR외에 기준 방법 중 최고였던 JRL의 성능도 기록함. JRL의 성능은 액션 공간에 의존하지 않음
- 위 실험의 결과에서 2가지 흥미로운 관찰이 있음
- 우리 모델은 대부분의 가지치기된 액션 공간 크기 선택에서 JRL을 능가함
- Clothing 데이터 셋을 예로 들어보면, Figure 3에서 4가지 평가 metric 모두 액션 공간 크기가 어떻든 JRL 위에 있음. (파란선이 모두 빨간선 위에 있음)
- 우리 모델의 성능은 가지치기된 액션 공간의 크기에 약간 영향을 받음을 알 수 있음
- 두 그림 모두에서 보이는 일반적인 경향은 더 작은 가지치기된 액션 공간이 더 나은 성능을 이끈다는 것. 이는 scoring fuction이 starting user 조건에 적합한 액션을 필터링하는 좋은 지표임을 의미함. 또 다른 가능한 이유는, 더 큰 액션 공간이 Rl;에서 더 많은 탐색을 요구하지만, 공정한 비교를 위해 모든 다른 액션 공간 선택에 대해 동일한 파라미터 (e.g., learning rates, training steps)를 설정했기 때문에 더 큰 액션 공간의 경우 suboptimal solution으로 이어졌을 수 있음.
- 우리 모델은 대부분의 가지치기된 액션 공간 크기 선택에서 JRL을 능가함
4.5 Multi-Hop Scoring Function
action pruning 및 reward 정의 외에도, scoring function은 KG 표현을 학습하는 것에 있어서 목적 함수의 일부로 사용됨.
디폴트로 우리는 표현 학습( representation learning )을 위해 1-hop scoring function을 사용함. 이 실험에서는 multi-hop scoring function이 우리의 방법의 추천 성능을 더욱 향상시킬 수 있는지 알아봄.
$$f(e_{0},e_{k}\mid\widetilde{r}_{k,j})=\left<\mathrm{e_{0}}+\sum_{s=1}^{j}\mathrm{r}_{s},\ \mathrm{e_{k}}+\sum_{s=j+1}^{k}\mathrm{r}_{s}\right>+b_{e_{k}},\qquad(9)$$
특히, 식(9)의 2--hop scoring function은 다음과 같음 : \(f(e_{0},e_{2}|{\tilde{r}}_{2},2)=\langle\mathrm{e}_{0}+\mathrm{r}_{1}+\mathrm{r}_{2},\mathrm{e}_{2}\rangle+b e_{2}\)
여기서 \({\tilde{r}}_{2,2}=\{r_{1},r_{2}\}\)는 엔티티 \(e_0\)와 \(\e_2)사이의 valid한 2-hop 패턴임.
이 함수는 entity 및 realtion 임베딩 학습을 위한 식 (14)의 목적함수에 연결됨.
$$J({\mathcal G}_{\mathrm{R}})=\sum_{e,e^{\prime}\in{\mathcal S}}\sum_{k=1}^{K}\operatorname{I}\{(e,{\tilde{r}}_{k,j},e^{\prime})\}\log\operatorname{P}(e^{\prime}|e,{\tilde{r}}_{k,j}),\qquad(14)$$
모든 추가 설정은 이전 액션 공간 실험에서 채택됨.
실험 결과는 Figure 3,4에 녹색 선으로 표시함.이는 2-hop scoring 함수로 학습된 새로운 모델을 의미.
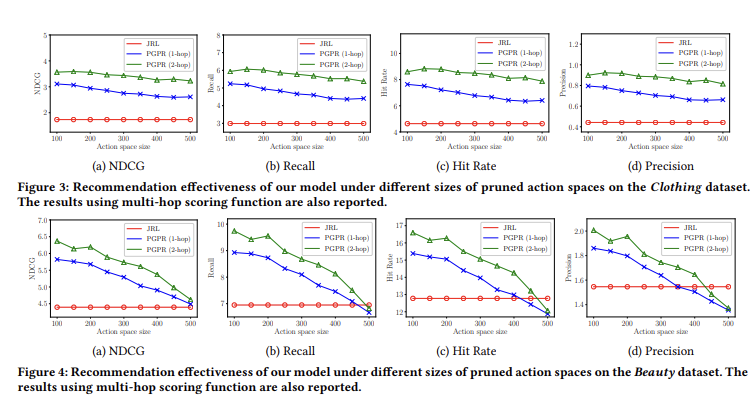
그림에서 볼 수 있듯이 우리의 2-hop PGPR 방법은 기본 모델(파란색 곡선)을 더 능가함. 이런 기능 향상은 주로 multi-hop scoring function의 효과에서 비롯되며, 이는 더 긴 거리에서 엔티티 간 상호작용을 포착함. 예를 들어, 사용자가 item을 구매하고 그 item이 category에 속하면(belong_to), 2-hop scoring function은 2-hop pattern인 {Purchase, Belong_to}를통해 User 엔티티와 Category 엔티티 간의 관련성을 강화함.
끄적 끄적 뇌피셜
여기서 말하는 1-hop(기존 방식 파란색 선), 2-hop(녹색 선)이게 앞에 Scoring Function for Reward. 부분에 해당하는 내용인 것 같다. 여기서 보상에 대한 scoring fucntion을 1-hop 패턴을 사용한다고 했는데 4.5 섹션에서 2-hop pattern 으로 늘려서 실험해본 듯.
사용자와 아이템간의 직접적인 관계만을 고려하던 1-hop에서 2-hop으로 늘려줌으로써 더 많은 정보를 고려해주는게 되니 성능이 향상되는듯.
4.5 앞부분에 kg 표현학습을 위해 디폴터로 1-hop 점수 함수를 쓴다고 했는데, 여기서 말하는 표현학습이 kg 의 엔티티와 relation을 저차원 벡터 공간으로 변환하는 과정이라고 한다면,
이 과정에서 scoring function은 엔티티 간의 관계를 벡터 연산으로 모델링 하는거라고 봐서 (앞에서 learning scoring function에서 엔티티와 relation의 임베딩을 어떻게 학습할 것인가 하는 내용이 있으니까) 여기서 말하는 1-hop은 Scoring Function for Reward에 해당하는 식이 아닐까 하는생각
4.6 Sampling Size in Path Reasoning
이 실험에서는 경로 추론을 위한 샘플링 크기가 우리 방법의 추천 성능에 미치는 영향을 연구함.
- 우리는 경로 길이가 3인 경우, 샘플링 크기의 9가지 다른 조합을 신중하게 설계했음.
- Table 4의 첫 번째 열에 나열된 각 튜플(K1, K2, K3)은 Algorithm 1에 설명된 대로 단계 t에서 상위 Kt 액션을 샘플링하는 것을 의미함
- 공정한 비교를 위해 샘플링 경로의 총 수(= K1 × K2 × K3)는 120으로 고정.(첫 번째 경우 제외)
- Clothing과 Beauty 데이터셋에서 실험을 수행하고 다른 매개변수의 기본 설정을 따름
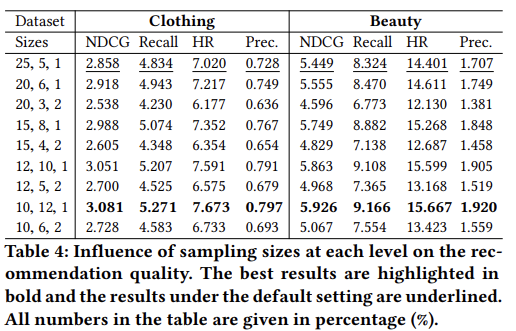
- 흥미롭게도, 첫 두 수준의 샘플링 크기가 좋은 경로를 찾는 데 더 중요한 역할을 한다는 것을 관찰할 수 있음.
- 예를 들어, (25, 5, 1), (20, 6, 1), (15, 8, 1), (12, 10, 1), (10, 12, 1)의 경우, 우리 모델은 나머지 경우보다 훨씬 더 좋은 성능을 보임.
=> 첫 두 단계의 액션 선택이 도달할 수 있는 아이템의 종류를 크게 결정한다는 것을 알 수 있음. 첫 두 단계가 결정되면, 정책 네트워크는 좋은 아이템으로 이어지는 최적의 액션을 선택하는 쪽으로 수렴하는 경향이 있음. 반면, 첫 두 수준에서 샘플링 크기가 클 경우, 우리 모델은 상당히 안정적이며, 이는 매개변수 튜닝을 위한 좋은 지침을 제공함.
4.7 History Representations
마지막으로, state history의 다양한 표현이 우리의 방법에 어떻게 영향을 미치는지 실험함.
- 우리는 \(h_t\)에 대해 세 가지 대안을 고려함
- 히스토리 없음(0-step)
- 마지막 엔티티 \(e_{t-1}\)와 관계 \(r_t\) (1-step)

0-step case에서 최악의 결과가 나옴. 이는 히스토리가 없는 상태 표현이 RL 에이전트가 좋은 정책을 학습하는데 충분한 정보를 제공하지 못한다는 것을 보여줌.
이와 별도로 2-step history를 사용하는 성능이 1-step history보다 약간 더 나쁘다. 그 이유 중 하나는 추가적인 히스토리 정보가 중복되거나 의사결정 과정에서 알고리즘을 오도할 수 있기 떄문.(추가적인 히스토리 정보가 중복되거나 불필요한 정보로 작용한듯 응)
5 CASE STUDY ON PATH REASONING
우리 모델이 추천을 어떻게 해석하는지 직관적으로 이해하기 위해, 이전 실험에서 생성된 결과를 기반으로 사례 연구를 제공함. 먼저, 추론 과정에서 모델이 발견한 경로 패턴을 연구한 후 다양한 추천 사례를 제시함
path patterns
path length가 3으로 고정된 경우, 우리의 method는 15가지의 서로 다른 path pattern을 발견하는데 성공함. 이 패턴들은 Figure 5에 집계된 형태로 표시됨.
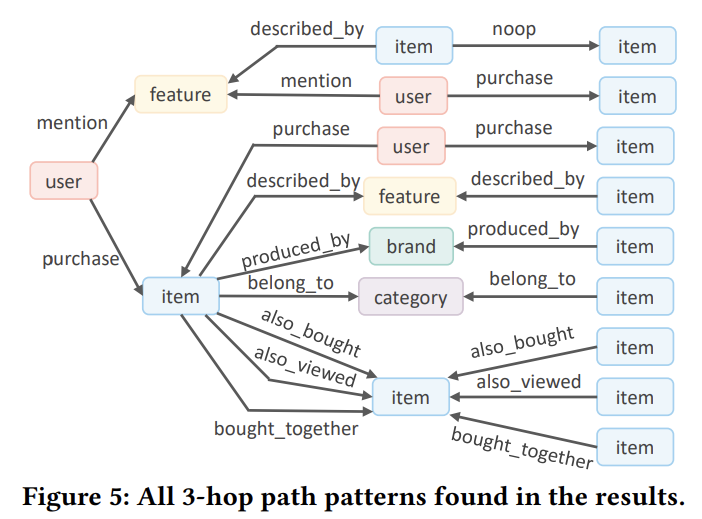
저 패턴 중 \(\left\{u s e r\stackrel{\rho u r c h a s e}{\longrightarrow}\;i t e m\stackrel{\rho u r c h a s e}{\longleftarrow}\;u s e r\stackrel{\rho u r c h a s e}{\longrightarrow}\;i t e m\right\}\) 이 패턴은 일종의 collaborative filtering이다.
Case study
Figure 6에 표시된 것처럼, 우리는 경로를 통해 추천을 해석하는 방법을 설명하기 위해 우리 method 생성한 여러 실제 사례를 제공.

- Case 1
- Beauty 데이터셋에서 나온 것
- user 가 2개의 feature word "norish"(영양)와 "lightening"(미백)로 described_by된 item "shampoo"를 purchase함.
- 다른 item "conditioner"도 일부 리뷰에서 이 두 가지 feature들을 포함하고 있었음. 따라서 모델은 이 user에게 "conditioner"를 추천했음
- Case 2
- 두명의 user가 모두 리뷰에서 "run"과 "comfort"라는 feature word를 언급함. 그래서 우리 method는 한 user 의 purchase history를 기반으로 그 사용자가 구매한 "running shoes"를 다른 사용자에게 추천함
- Case 3
- user 가 item "iPhone"을 구매하고 "charger line"도 조회함. 다른 user 가 "phone case"를 구매할 때 "charger line"도 함께 구매하는 것을 고려해, 우리 method는 해당 user에게 "iPhone Case"를 추천함
- Case 4
- user가 "Hello Kitty" 카테고리에 속한 item "neck chain"를 구매한 사례를 나타냄. 따라서 우리 방법은 user에게 같은 카테고리 "Hello Kitty" 에 속하는 다른 아이템 "key chain"을 추천함.
우리는 PGPR 방법이 유망한 추천 결과를 달성할 뿐만 아니라 추천을 위한 다양한 추론 경로를 효율적으로 찾을 수 있다고 결론 지었음.
6 CONCLUSIONS AND FUTURE WORK
우리는 미래의 intelligent agents는 의사 결정을 위해 지식을 명시적으로 추론할 수 있는 능력을 가져야 한다고 믿음.
본 논문에서는 해석 가능한 추천을 위해 지식 그래프를 통한 RL 기반 추론을 제안함.
이를 위해 우리는 Policy-Guided Path Reasoning (PGPR)이라는 방법을 개발함.
제안된 소프트 보상 전략, 사용자 조건부 액션 가지치기 전략, 멀티-홉 스코어링 접근 방식을 기반으로, 우리의 RL 기반 PGPR 알고리즘은 뛰어난 추천 결과를 달성할 수 있을 뿐만 아니라, 설명 가능성을 위해 추론 절차를 공개함.
여러 state-of-art baselines와 비교해 우리의 접근 방식의 성능을 검증하기 위해 광범위한 실험을 수행했음.
PGPR 접근 방식은 flexible graph reasoning framework로, product 검색 및 social recommendation과 같은 많은 다른 그래프 기반 작업에도 확장될 수 있음에 주목해야 함.
또한, 우리는 시간에 따라 변화하는 그래프를 모델링하여 dynamic decision support를 제공하기 위해 PGPR접근 방식을 확장할 수 있음.
Question 1

분명 Scoring Function for Reward에서는 user와 item 엔티티간의 1-hop 패턴을 사용한다고 했는데, =>
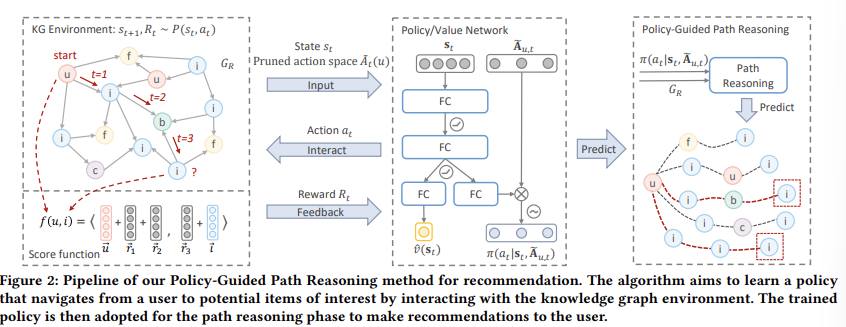
왜 그림 2에서는 1-reverse k-hop 패턴을 다 고려한 scoring function을 쓰고 있는지=>
내가 생각한 답 : 3.2 의 reward 부분에서 terminal state 에 대한 보상 R_T에서만 또다른 scoring function 을 기반으로 soft reward를 제공한다고 했으니, 중간 과정 보상인 R_t는 그림 2와 같이 1-reverse k-hop 패턴을 고려한 scoring function을 사용하고 최종 state에서 R_T만 1-hop 패턴을 고려하는게 아닌가...
공식 Answer 1 :
'kdd > knowledge graph 논문 리뷰' 카테고리의 다른 글
| [강화학습]PGPR과 ReMR을 읽기 위한 base (0) | 2024.07.28 |
|---|---|
| [KG_2019]KGAT: Knowledge Graph Attention Network for Recommendation (0) | 2024.07.24 |
| [KG]PGPR을 읽고 ReMR을 읽으면서 느낀 둘 사이의 연관성 (2) | 2024.07.22 |
| [KG_2019]KPRN(Explainable Reasoning over Knowledge Graphs for Recommendation) (1) | 2024.07.22 |
| [KG_2022]ReMR(Multi-level Recommendation Reasoning overKnowledge Graphs with Reinforcement Learning) (0) | 2024.07.14 |


