
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 자료구조
- Recommendation
- Python
- Deque
- explainable recommendation
- isalnum()
- kg
- LSTM
- 동적 프로그래밍
- Dynamic Programming
- 우선순위 큐
- bfs
- Algorithm
- Knowledge graph
- 프로그래머스
- 추천시스템
- 백준
- 알고리즘
- find()
- isnumeric()
- isdigit()
- 파이썬
- 그래프 탐색
- 코테
- knowledge
- 정렬
- isalpha()
- DP
- 그래프
- Stack
- Today
- Total
데린이 고인물되기
[KG_2022]ReMR(Multi-level Recommendation Reasoning overKnowledge Graphs with Reinforcement Learning) 본문
[KG_2022]ReMR(Multi-level Recommendation Reasoning overKnowledge Graphs with Reinforcement Learning)
데린이 성장 중 2024. 7. 14. 12:44https://medium.com/codex/understanding-ontologies-and-knowledge-graphs-4664afc4f961
Understanding Ontologies and Knowledge Graphs
Knowledge graphs have taken many by storm. Its ability to represent data and derive inferences have proved to be a game changer for…
medium.com
사전에 읽으면 좋을 것 같은 논문:
https://dl.acm.org/doi/pdf/10.1145/3292500.3330838
https://www.cs.cmu.edu/~mmv/papers/04aaai-pat.pdf (abstract MDP에 관한 논)

예시 시나리오
- 하위 레벨 초기 상태 예시:
- 사용자가 구매한 특정 브랜드의 화장품에 대한 정보(예: "아르마니 립스틱")를 초기 상태로 설정합니다.
- 상위 레벨 추상화 상태 정의:
- "아르마니 립스틱"이라는 하위 레벨 상태를 "럭셔리 화장품 브랜드"와 같은 상위 레벨 상태로 추상화합니다.
- 상위 레벨 정책 학습:
- 상위 레벨에서 "럭셔리 화장품 브랜드"에 대한 사용자 관심사를 학습합니다.
- 이를 통해 "사용자는 럭셔리 브랜드를 선호한다"는 상위 레벨 정책을 설정합니다.
- 하위 레벨 정책 학습:
- 상위 레벨 정책을 바탕으로 하위 레벨에서 "아르마니 립스틱"과 관련된 더 구체적인 제품 추천 정책을 학습합니다.
- 상위 레벨 지식을 활용하여 하위 레벨의 복잡도를 줄이고, 더 빠르게 수렴합니다.
3.1.1 에 두번째 방식이라고 나온 설명 보충 설명
내가 이해한 바로는 ... low-level KG에서 PGPR같은 single-level reasoning method를 사용해서 경로를 추출을 함. 그리고 그 경로에 엔티티와 relation이 있을건데, 각 엔티티를 \(r_{ISA}\) 관계를 기반으로 상위 레벨(\(l\)) kg로 노드를 연결을 함. 그리고 상위 레벨 kg에서 하위 경로랑 연결된 노드들에 대해 하위 경로랑 동일한 relation으로 이어주는거임. 그렇게 상위 레벨에서 경로 추출을 하고, 그렇게 만들어진 경로가 \(\hat{\mathcal{G}}^l\)가 되는거임.
그리고 이 경로를 기반으로 상위 레벨 MDP를 다시 정의하고, 여기까지 설명돼있는듯
3.1.2의 weighting function 이해 다시 해보기
- ### 샘플링 기반 가중치 계산을 통한 Abstract MDP 이해
샘플링 기반 가중치 계산을 통해 Abstract MDP를 이해하는 방법을 설명해 드리겠습니다.
### 당신의 이해:
#### 시나리오:
1. **Ground 상태**:
- **State1**: A가 립스틱을 구매함
- **State2**: A가 파운데이션을 구매함
2. **추상 상태**:
- A가 화장품을 구매함 (State1과 State2가 이 추상 상태로 매핑됨)
3. **샘플링 데이터**:
- State1은 2번 샘플링됨
- State2는 1번 샘플링됨
- 따라서, 추상 상태(A가 화장품을 구매함)는 \(2 + 1 = 3\)번 샘플링됨
4. **가중치 계산**:
- State1의 가중치: \( \frac{2}{3} \)
- State2의 가중치: \( \frac{1}{3} \)
### 이론적 설명
1. **Abstract MDP 설정**:
- Ground MDP \( M_0 \)와 Abstract MDP \( M_l \)을 정의
- 상태 추상화 함수 \( \phi \)와 가중치 함수 \( \omega \)를 사용하여 여러 상태를 집계하여 Abstract MDP \( M_l \)을 생성
2. **상태 추상화 함수 \( \phi \)**:
- \( \phi \)는 Ground 상태를 추상 상태로 매핑
- 당신의 경우, \( \phi(\text{state1}) = \text{cosmetics} \)이고 \( \phi(\text{state2}) = \text{cosmetics} \)
3. **가중치 함수 \( \omega \)**:
- \( \omega \)는 각 Ground 상태가 추상 상태에 기여하는 정도를 결정
- 샘플링 과정에서 각 Ground 상태의 빈도를 기준으로 계산
4. **샘플링 과정**:
- 하위 레벨 정책 \( \tilde{\pi_0} \)에 따라 Ground 상태를 샘플링
- 각 Ground 상태의 빈도를 계산하고 이를 정규화하여 가중치를 구함
### 계산 예시:
당신의 시나리오를 기준으로:
- **State1**: A가 립스틱을 구매함 (2번 샘플링됨)
- **State2**: A가 파운데이션을 구매함 (1번 샘플링됨)
가중치는 다음과 같이 계산됨:
\[ w(\text{state1}) = \frac{\text{state1이 나타난 횟수}}{\text{전체 나타난 횟수}} = \frac{2}{3} \]
\[ w(\text{state2}) = \frac{\text{state2가 나타난 횟수}}{\text{전체 나타난 횟수}} = \frac{1}{3} \]
이 가중치는 Abstract MDP \( M_l \)의 추상 전이 함수와 보상 함수를 계산하는 데 사용됨.
### 결론:
당신의 이해는 정확합니다. 샘플링을 통해 각 Ground 상태의 가중치를 결정하고, 이 가중치를 Abstract MDP의 전이 함수와 보상 함수 계산에 사용하는 방법을 정확히 설명하셨습니다. 특히, 각 상태의 가중치가 해당 상태의 발생 빈도를 전체 발생 빈도로 나눈 값이라는 점을 잘 이해하셨습니다.
더 궁금한 점이 있거나 추가 설명이 필요하시면 언제든지 말씀해 주세요!
(이전까지 읽은 내용 대충 생각 정리) \(\hat{\mathcal{G}}^l\)
- 다중 레벨 KG를 추론하는 가장 간단한 방법은 고수준 관계를 다른 저수준 관계와 동일하게 취급해서, 이를 단일 그래프로 축소하는 것.
- -> P1과 P2를 만족할 수 없음. 그리고 추론된 경로가 이해하기 어려울 수 있음
- 또 다른 방법은 각 레벨에서 MDP를 정의하는 것. 각 레벨에서 MDP정의하고 고수준에서 단일 홉(단일 개념)간의 연결만 고려됨
- -> 고수준 MDP가 하위 수준의 세부 연결 정보를 모두 담지 못할 수 있음(고수준 MDP는 개념 간의 연결만 고려하므로 하위 수준에서의 구체적인 전이 경로를 반영하지 않음)
- ->고수준 MDP에서 생성된 일부 경로는 실제 하위 수준에서 존재하지 않을 수 있음.
- -> 고수준에서 합리적으로 보이는 경로가 실제로는 하위수준에서 연결되지 않을 수 있음
- -> 각 레벨간 지식을 어떻게 전이할지, 각 추론 홉에서 올바른 레벨을 어떻게 선택할지 불분명. infeasible한 추론 경로를 뽑을수도 있음
- 그래서 해당 논문에서 제안하는게 abstract MDP
- infeasible path를 추출하지 않기 위해 저수준 KG를 염두에 두고 고수준 KG를 통해 추론하는 것이 중요.
- 고수준 추론 경로를 abstract MDPs(ground MDP를 기반으로 정의됨.)로 정의할 것을 제안
- => 1. infeasible 경로를 추출하지 않음을 증명
- => 2. 고수준에서 학습된 추론 정책이 저수준 추론을 효과적으로 안내할 수 있음(sec 3.1.3)
- * abstract MDP : ground MDP의 여러 상태를 하나의 상태로 집계하여 생성된 MDP
3.2 Cascading Actor-Critic
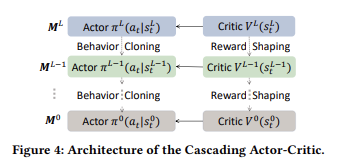
- 우리는 Cascading Actor-Critic 알고리즘을 설계함
- \( M^{L},M^{L-1},...,M^{0} \)의 정책을 학습하기 위해
- 기본 아이디어 : 고수준 정책을 학습해 사용자에 대한 글로벌한 이해를 얻고 나서 더 세부적인 정보를 고려해 더 낮은 수준에서 점진적으로 고수준 정책을 미세 조정하는 것.
- -> top-down 전략 채택(그림 4) : 상위 레벨에서 하위 레벨로 내려가는 전략
- 처음에 \( M^{L} \)을 해결하면서 가장 높은 레벨의 정책인 \( \pi^{L} \) 을 학습함. 학습된 지식( \( \pi^{L} \) ) 은 L-1로 전달돼서 \( \pi^{L-1} \) 배울 때 효과적으로 검색 공간을 가지치기 할 수 있음. 그리고 더 만족스러운 솔루션으로 수렴을 보장할 수 있음.
- 이 과정이 반복되면서 순차적으로 \( \pi^{L-1}, \pi^{L-2},..., \pi^{0} \) 을 얻음.
3.2.1 Actor-critic learning at the top level( \( l = L \))
- actor-critic learning 이란:?
- 강화학습 알고리즘의 한 종류로, 배우(actor)와 비평가(critic) 두가지 구성 요소를 결합해 학습 효율성과 성능을 향상시키는 방법
- actor
- 역할 : 현재 정책을 기반으로 행동을 선택하는 역할. 정책을 개선하는 것을 학습
- 기능 : 주어진 상태에서 어떤 행동을 취할지에 대한 확률 분포를 출력
- critic
- 역할 : 배우가 선택한 행동을 평가함. 행동이 얼마나 좋은지 나쁜지를 추정해 배우에게 피드백 제공
- 기능 : 현재 상태 또는 상태-행동 쌍의 기대 보상을 추정. 이 값은 정책 업데이트하는 데 사용됨.
- actor
- -> 정책(배우)과 가치 함수(비평가) 를 별도의 네트워크로 두어서 학습 과정이 안정적이고 효율적일 수 있음
- 순차적 의사 결정이 필요한 다양한 분야에서 사용
- 강화학습 알고리즘의 한 종류로, 배우(actor)와 비평가(critic) 두가지 구성 요소를 결합해 학습 효율성과 성능을 향상시키는 방법
- 최상위 수준에서의 학습은 상위 수준의 지식을 활용할 필요가 없어서 다른 수준보다 학습이 간단함.
여기서 질문은... abstract MDP에 대한 정책을 어떻게 학습하는가?임.
- 방정식 (4)와 같이 가중치 함수를 정의함으로써 추상 MDP의 샘플을 직접 얻을 수 있음.

- 식 (4)는 기저 MDP(\( M^{0} \))의 상태들을 추상 MDP(\( M^{l} \))로 집계하는 데 중요함.
- 이 과정은 하위 수준(ground MDP (\( M^{0} \)) ) 에서 샘플링하고, 이 샘플들을 상태 추상화 함수 \( \phi^{l} \)을 사용해 추상 수준\(l\)로 매핑하는 것을 포함함
- 단계별 매핑은 높은 수준의 샘플이 기저 수준의 동적 관계를 정확하게 반영하도록 보장하는데 필수적임.
-
- -> 따라서 전통적인 강화학습 방법을 사용해 추상 MDP를 해결 할 수 있음
- 이 논문의 방법과 다른 점은..논문의 방법은 최적화 중에 먼저 하위 수준에서 샘플링을 하고, 그런 다음 하위 수준 샘플을 \( \phi^{l} \) 로 수준 \( l \)로 매핑해 고수준 샘플(\( s_{t}^{l}, a_{t}, s_{t+1}^{l}, r_{t+}^{l} \))을 얻어야 한다는 점에서 다름.
- 이렇게 고수준 데이터(샘플)를 얻고 actor-critic방법을 사용해 추상 MDP에서 정책을 학습하는 듯
- 이 논문의 방법과 다른 점은..논문의 방법은 최적화 중에 먼저 하위 수준에서 샘플링을 하고, 그런 다음 하위 수준 샘플을 \( \phi^{l} \) 로 수준 \( l \)로 매핑해 고수준 샘플(\( s_{t}^{l}, a_{t}, s_{t+1}^{l}, r_{t+}^{l} \))을 얻어야 한다는 점에서 다름.
- -> 따라서 전통적인 강화학습 방법을 사용해 추상 MDP를 해결 할 수 있음
- 우리는(이 논문) RL 방법 중 하나인 actor-critic을 사용(sec3.2.2)
- (경로 추론에서 효과적이고 고수준 지식 전이를 용이하게 함)
Actor \(\pi^{L}\)
Actor(또는 정책 네트워크)는 상태에 따라 각 행동을 취할 확률을 출력함. PGPR논문(나중에 따로 리뷰할 예정)을 따르며, 우리는 actor을
- three-layer feed-forward network로 설계하고,
- 활성화 함수로 Exponential Linear Unit(ELU)을 사용하며,
- 과적합 방지를 위해 드롭아웃을 활용함
구체적인 수식:
$$ x = dropout(ELU(dropout(ELU(s_{t}^{L}W_{1}))W_{2})) \quad \quad (5) $$
$$ \pi^{L}(\cdot | s_{L}^{t})=softmax(A_{t}\odot(xW_{a})) \quad \quad (6) $$
- 여기서 \( W_{1}\in\mathbb{R}^{d_{1}\times d_{2}},W_{2}\in\mathbb{R}^{d_{2}\times d_{3}},W_{a}\in\mathbb{R}^{d_{3}\times d_{a}} \)는 학습할 파라미터.
- \( s_{t}^{L} \) 는 \(s_{t}^{L}\)의 임베팅 벡터로, \(s_{t}^{L}\) 내 모든 개념, 엔티티, 관계의 임베딩을 연결해 계산됨.
- 임베딩은 JOIE[8]을 이용해 학습되며, 이는 온톨로지와 인스턴스 뷰를 공동으로 인코딩하는 최신 KG 임베딩 기법임
- \( \odot \)는 element-wist product
- 이를 통해 네트워크가 현재 상태에서 가능한 행동만을 선택적으로 고려할 수 잇
- \( A_{t} \)는 액션 공간 \( A_{t} \)에서만 액션을 선택하도록 사용하는 이진벡터
- \( A_{t} \)의 \( i \)번쨰 항목은 \( i \)번째 액션이 \( A_{t} \)에 있으면 1이고, 그렇지 않으면 0
- 더보기
예를 들어, AtA_t가 [1, 0, 1, 0]이라면, 이는 다음을 의미합니다:
- 첫 번째 행동(인덱스 0)은 가능한 행동입니다.
- 두 번째 행동(인덱스 1)은 불가능한 행동입니다.
- 세 번째 행동(인덱스 2)은 가능한 행동입니다.
- 네 번째 행동(인덱스 3)은 불C가능한 행동입니다.
- PGPR논문을 따라 액션 공간을 가지치기 해서 최대 \( N_{m} \) 후보 액션을 유지
- 식 (6) 에서처럼 최종 변환된 벡터 \(x\)는 소프트 맥스 함수를 통해 각 행동의 확률로 변환됨
Critic \(V^{L}\)
Critic(또는 value network)는 주어진 \(s^{L}_{t}\)에서 \(\pi^{L}\)가 얻을 것으로 예상되는 보상을 출력함. Critic은 Actor와 첫 2개의 레이어를 공유하고, 출력 레이어에서 달라진다 :
$$ V^{L}(s^{L}_{t}=xW_{c}) \quad \quad (7) $$
- \(W_{c}\in\mathbb{R}^{d_{3}\times 1}\) 는 학습할 파라미터
강화 학습 에이전트가 현재 상태에서 얼마나 좋은 상태에 있는지 평가하는 역할을 하는듯
- actor와 첫 2개 feed forward 레이어 공유함
- -> 입력 데이터를 처리하여 중간 표현 x를 생성함
- 출력 레이어 :
- critic의 출력 레이어는 중간 표현 x를 입력으로 받아 최종적으로 기대 보상 값을 출력함. 그 계산식이 7번 식
Optimization(actor-critic 알고리즘을 써서 actor와 critic네트워크를 학습하는 방법)
각 iteration에서 우리는 \( P_{0} \)와 \( \tilde{\pi}_{0} \)에 따라 \( M_{0} \)에서 샘플 (\( s_{t}^{0}, a_{t}, s_{t+1}^{0}, R(s_{t}^{0},a_{t}) \))를 얻음.
여기서 \( \tilde{\pi}_{0}(a_{t}|s_{t}^{0}) = \pi{L}(a_{t}| \phi_{L}(s_{t}^{0})) \)
샘플을 레벨 \( L \)로 매핑함으로써, 고수준 샘플 \((\phi^L\left(s_t^0\right), a_t, \phi^L\left(s_{t+1}^0\right), \mathcal{R}^0\left(s_t^0, a_t\right))\) 을 얻으며, 이건 actor과 critic을 업데이트하는데 사용됨.
- \( M_{0} \)에서 샘플 (\( s_{t}^{0}, a_{t}, s_{t+1}^{0}, R(s_{t}^{0},a_{t}) \))를 얻음
- 여기서 \( s_{t}^{0}\)는 현재 상태
- \(a_{t}\)는 현재 상태에서 취한 행동
- \(s^{0}_{t+1}\)은 다음 상태
- \( \mathcal{R}^0\left(s_t^0, a_t\right) \)는 현재 상태에서 행동을 취한 후 얻은 보상
- 그 샘플을 레벨 \( L \)로 매핑함으로써, 고수준 샘플 \((\phi^L\left(s_t^0\right), a_t, \phi^L\left(s_{t+1}^0\right), \mathcal{R}^0\left(s_t^0, a_t\right))\) 을 얻음
- 구체적으로, 우리는 \(J_{\pi^L}+J_{V^L}\)을 최소화하여 actor과 critic을 학습함:
- $$ J_{\pi^L}=-\log \pi^L\left(a_t \mid \phi^L\left(s_t^0\right)\right) V^L\left(\phi^L\left(s_t^0\right)\right) \\ \quad \quad (8) $$
$$ J_{V^L}=\left\|\mathcal{R}^0\left(s_t^0, a_t\right)+V^L\left(\phi^L\left(s_{t+1}^0\right)\right)-V^L\left(\phi^L\left(s_t^0\right)\right)\right\|^2 \quad \quad (9) $$
- $$ J_{\pi^L}=-\log \pi^L\left(a_t \mid \phi^L\left(s_t^0\right)\right) V^L\left(\phi^L\left(s_t^0\right)\right) \\ \quad \quad (8) $$
- 고수준 샘플을 사용해 Actor과 critic을 업데이트하는데, 이를 위해 두가지 손실함수 \(J_{\pi^L}\)과 \(J_{V^L}\)를 최소화함.
- \(J_{\pi^L}\) : actor의 손실함수
- - 현재 상태 ( \(\phi^L\left(s_t^0\right)\) )에서 취한 행동(\(a_t\))의 로그 확률 \(\times\) 현재 상태( \(\phi^L\left(s_t^0\right)\) )의 가치 함수
- -> 가치가 높은 헹동의 확률을 높이도록 학습
- 가치가 높은 행동의 확률을 높이기 위해서 손실함수에 마이너스를 붙이는거임(마이너스가 붙음으로써, 가치가 높은 상태일수록 해당 행동의 확률이 높아지도록 학습)
- (V가 높으면, \(log\pi\) 높이도록 학습해야하는데 마이너스가 붙어야 이때 loss가 줄어들게 됨)
- -> 가치가 높은 헹동의 확률을 높이도록 학습
- - 현재 상태 ( \(\phi^L\left(s_t^0\right)\) )에서 취한 행동(\(a_t\))의 로그 확률 \(\times\) 현재 상태( \(\phi^L\left(s_t^0\right)\) )의 가치 함수
- \( J_{V^L} \) : Critic의 손실함수
- 현재 상태 ( \(\phi^L\left(s_t^0\right)\) )에서 얻은 보상과 다음 상태의 가치함수, 현재 상태의 가치 함수의 차이를 최소화함.
- -> 이를 통해 critic은 상태의 가치를 정확하게 예측하도록 학습
- 이 손실 함수는 상태 가치 함수 \(V^{L}\)의 예측 오류를 최소화하는데 초점을 두고 있음
- 즉각적인 보상 \(R^{0}(s^{0}_{t},a_t)\):
- 상태 \(s^{0}_{t}\)에서 행동 \(a_t\)를 취했을 떄의 즉각적인 보상
- 에이전트가 해당 행동을 수행한 후 즉시 받는 보상 값
- 다음 상태의 가치 \(V^L\left(\phi^L\left(s_{t+1}^0\right)\right)\) :
- 다음 상태 \(\phi^L(s^{0}_{t+1})\)의 예측된 가치
- critic 네트워크는 현재 상태에서 기대되는 총 보상을 예측함
- \(R^0\left(s_t^0, a_t\right)+V^L\left(\phi^L\left(s_{t+1}^0\right)\right)\) : 현재 상태에서 행동을 취한 후, 얻은 즉각적인 보상과 다음 상태에서 기대되는 미래보상의 합(현재 상태에서의 총 보상을 나타냄)
- 이 값을 현재 상태 \(\phi^L\left(s_t^0\right)\)의 가치 \(V^L\left(\phi_L\left(s_{t+1}^0\right)\right)\)와 비교하는 것.
- 목표는 두 값이 같아지도록 하는것. 즉, critic 네트워크가 현재 상태의 가치를 정확하게 예측하도록 학습시키는 것(오차가 작을수록 손실함수 값이 작아짐)
- 이 값을 현재 상태 \(\phi^L\left(s_t^0\right)\)의 가치 \(V^L\left(\phi_L\left(s_{t+1}^0\right)\right)\)와 비교하는 것.
- 정확한 가치 평가를 통해 에이전트는 보다 더 나은 결정을 내릴 수 있게 됨
- 현재 상태 ( \(\phi^L\left(s_t^0\right)\) )에서 얻은 보상과 다음 상태의 가치함수, 현재 상태의 가치 함수의 차이를 최소화함.
- \(J_{\pi^L}\) : actor의 손실함수
Interpretation.
- \( J_{V^L} \)을 최소화 함으로써, critic \(V^L\)는 고수준 상태의 가치(예상 보상)를 추정하는 방법을 학습함.
- \(J_{\pi^L}\)을 최소화 함으로써, actor은 더 가치 있는 상태로 이어지는 행동의 확률을 증가시킴.
- 식 (9)에서 알 수 있듯이, 저수준 상태의 보상은 고수준 상태의 조상에 영향을 미침.
- 예를 들어,저수준에서 Alice가 특정 화장품을 좋아한다는 것을 발견하면, 고수준 사애에서 화장품이 보상을 받고, \(\pi^L\)은 다른 화장품에 대해 더 많이 탐색하게 됨
3.2.2 Actor-critic learning at lower level( \( l < L \))
하위 레벨의 actor과 critic은 \(\pi^L\) 과 \(V^L\)와 동일한 네트워크 구조를 채택함.
여기서 질문은.. 레벨 \(l+1\)의 지식을 효과적으로 활용할 수 있도록
\(\pi^l\) 과 \(V^l\)을 어떻게 학습할 수 있는가?임.
- 우리의 해결책은 행동 복제(behavior cloning)와 보상 형성(reward shaping)을 통합하는 것.(fig 4)
하위레벨에서 actor와 critic을 학습하는 방법에 대해 설명하고 있음. 하위 레벨에서의 학습은 상위 레벡의 지식을 활용해 더욱 효과적으로 이루어진다. 이를 위해 두가지 주요 기법을 사용하는데 이게 행동 복제와 보상 형성.
Behavior cloning(행동 복제) -> \(\pi^l\) 학습
Lemma 1에 따르면, 추상 MDP에서의 최적 정책은 기저 MDP에서의 최적 정책과 밀접하게 관련되어 있음.
- \(M^l\)을 기저 MDP로, \(M^{l+1}\)을 추상 상태 함수 \(\phi^1\)를 사용하는 추상 MDP로 고려해보자.
- 그러면 기저 정책 \(\pi^l\)을 \(\pi^{l+1}\)로 초기화하는 것이 유익하다는 것을 알 수 있음(상위 레벨에서 학습된 지식을 하위 레벨에 그대로 반영할 수 있기 떄문에)
-
더보기왜 유익?
- 상위 레벨의 최적 정책은 하위 레벨의 최적 정책과 밀접하게 관련되어 있음. 상위 레벨에서 잘 작동하는 정책은 하위 레벨에서도 좋은 출발점이 된다.
- 예를 들어, 특정 상품군(화장품)에 대한 상위 레벨의 정책이 있다면, 이 정책을 하위 레벨(개별 화장품 항목)에 그대로 적용하면 유사한 성능을 기대할 수 있음 -
더보기구체적인 과정
- 상위 레벨의 정책 (\(\pi^{l+1}\))을 사용해 여러 경로를 생성함
- 이 경로들을 하위 레벨의 정책(\(\pi^{l}\))을 학습하기 위한 기준 레이블로 사용
- 하위 레벨의 정책은 초기화 된 후, critic을 기반으로 더욱 개선됨 - 따라서 \(\pi^{l}\)을 \(\pi^{l+1}\)의 행동을 복제하여 초기화 함.
- 즉, \(\pi^{l+1}\)을 사용해 경로를 생성하고, 이 경로를 초기 \(\pi^{l}\)을 학습하기 위한 기준 레이블로 사용.
- 그 후, \(\pi^{l}\)은 \(\pi^{L}\)과 동일한 방식으로 critic을 기반으로 개선됨(식 (8))
Reward shaping(보상 형성) -> \(V^l\) 학습
\(V^{l}\)을 더 잘 안내하기 위해, 우리는 이론적으로 보장이 잘 되어있는 보상 형성[15]을 사용함. 보상 형성은원래 MDP에서 제공하는 희소한 보상 외에 추가 보상을 추가해 학습 과정을 안내하는 절차임.
- 구체적으로, \(\mathbf{M}^l=\left\{\mathcal{S}^l, \mathcal{A}, \mathcal{R}^l, \mathcal{P}^l\right\}\) 을 해결하기 위해, 우리는 \(\hat{\mathbf{M}}^l=\left\{\mathcal{S}^l, \mathcal{A}, \mathcal{R}^l+\mathcal{F}^l, \mathcal{P}^l\right\}\)라는 형성된 MDP를 만듦. 여기서 형성함수 \( \mathcal{F}^l \)는 \(V^{l+1}\)을 기반으로 정의됨:
- \(F^{l}(s_{t}^{l},s_{t+1}^{l})=V^{l+1}(\phi_{l+1}(s_{t+1}^{0}))-V^{l+1}(\phi_{l+1}(s_{t}^{0})) \quad\quad (10)\)
- \(s_{t}^{l}=\phi^{l}(s_{t_{-}}^{0})\;\mathrm{and}\;s_{t+1}^{l}=\phi^{l}(s_{t+1}^{0})\)
- 이런 가치함수 기반 보상 형성이 더 빠른 수렴을 가능하게 하며, \({\hat{M}}_{l}\)를 해결해 학습한 근사 최적 정책이 여전히 \(\mathbf{M}^{l}\)에서 근사 최적임이 증명되었음[15]
- 따라서 우리는 \(\mathbf{M}^{l}\) 대신 \({\hat{M}}_{l}\)을 해결함
- 이는 식(9)를 식(11)로 바꿔서 달성됨
- $$ J_{V^L}=\left\|\mathcal{R}^0\left(s_t^0, a_t\right)+V^L\left(\phi^L\left(s_{t+1}^0\right)\right)-V^L\left(\phi^L\left(s_t^0\right)\right)\right\|^2 \quad \quad (9) $$
- $$J_{V^{l}}=\|{\mathcal{R}}^{0}(s_{t}^{0},a_{t})+{\mathcal{F}}^{l}(s_{t}^{l},s_{t+1}^{l})+V^{l}(\phi^{l}(s_{t+1}^{0}))-V^{l}(\phi^{l}(s_{t}^{0}))\|^{2}\ \ (11)$$
- \(F^{l}(s_{t}^{l},s_{t+1}^{l})=V^{l+1}(\phi_{l+1}(s_{t+1}^{0}))-V^{l+1}(\phi_{l+1}(s_{t}^{0})) \quad\quad (10)\)
- 보상 형성의 필요성
- 하위 레벨에서 학습을 더 잘 안내하기 위해 추가적인 보상을 제공함. 원래의 보상 외에도 추가적인 정보를 통해 학습을 도움
- 예를 들어, 특정 행동이 좋은 결과로 이어진다면, 그 행동에 대한 추가 보상을 제공해 에이전트가 더 빠르게 학습할 수 있도록 함
- 구체적인 과정
- 보상 형성은 추가적인 보상함수를 정의해 원래의 보상에 더함.
- 이 추가 보상함수는 상위 레벨의 가치 함수 \(V^{l+1}\)을 기반으로 함
- 구체적으로, 상태 전이 (\(s^{l}_{t}, s^{l}_{t+1}\))에 대해 상위 레벨에서의 가치 변화량을 추가 보상으로 사용함
- 즉, 현재 상태와 다음 상태에서의 가치 함수 차이를 보상에 더함.
- 그림 5는 보상 형성이 상위 레벨(\(\mathrm{M}^{1}\))의 지식을 하위 레벨(\(\mathrm{M}^{0}\))로 어떻게 전이 시키는지를 보여줌.

- \(\mathrm{M}^{1}\)을 학습한 결과, \(\mathrm{V}^{1}\)은 Alice가 스포츠 신발보다 얼굴 화장을 더 좋아한다는 것을 알게됨.
- 즉, \(V^{1}(s_{1}^{1})\,>\,V^{1}(s_{1}^{1\,\prime})\) : 얼굴 화장 상태 \(s^{1}_{1}\)의 가치( \(V^{1}(s_{1}^{1})\) )가 스포츠 신발 상태 \( s_{1}^{1\,\prime} \)의 가치 \( V^{1}(s_{1}^{1\,\prime}) \)보다
- 이 지식은 형성 함수 \({\mathcal{F}}^{0}\)에 의해 레벨 0으로 전이되며, 이는 즉시 Alice가 Acalme 스니커즈보다 Luminous Silk Foundation을 더 좋아한다는 것을 밝혀줌.이는 Luminous Silk Foundation 에 더 높은 보상을 할당함으로써 이루어짐(즉,\(R^{0}(s_{0}^{0},a_{0})+\mathcal{F}^{0}(s_{0}^{0},s_{1}^{0})>\mathcal{R}^{0}(s_{0}^{0},a_{0}^{\prime})+\mathcal{F}^{0}(s_{0}^{0},s_{1}^{0})\) )
최종 상태(t = T)에서만 0이 아닌 값을 가지는 희소 보상 \({\mathcal{R}}^{0}\)과 비교하여, \({\mathcal{F}}^{0}\)는 각 \(t\leq T\)에 유용한 정보를 제공하며, 이는 탐색 공간(search space)를 가지치기하고 레벨0에서의 학습을 더 만족스러운 해결책으로 수렴하도록 안내함.
- 희소 보상 \({\mathcal{R}}^{0}\) :
- 희소 보상은 보통 MDP에서 최종 상태(t = T)에 도달했을 때만 의미 있는 값을 가짐
- 학습 에이전트는 주로 최종 상태에서 얻는 보상을 기반으로 학습.
- 이는 중간 상태에서의 보상이 거의 없기 때문에 학습이 느리고 비효율적일 수 있음
- 형성 보상 \({\mathcal{F}}^{0}\):
- 형성 보상은 각 시간 단계 \(t\leq T\) 유용한 추가 정보를 제공함.
- 이는 상위 레벨의 가치 함수를 기반으로 추가 보상을 제공하여, 중간 상태에서도 학습을 효과적으로 안내함
- 구체적으로, 상태 간의 전이에서 상위 레벨의 가치 변화에 기반한 보상을 제공(식 (10) 참고)
- 형성 보상의 효과
- 탐색 공간 가지치기 :
- 각 시간 단계에서 유용한 보상을 제공 -> 에이전트는 보다 효율적으로 탐색 공간을 줄일 수 있음
- 이는 불필요한 경로를 탐색하는 시간을 줄이고, 더 유망한 경로를 탐색하도록 도움
- 더 빠른 수렴
- 형성 보상은 중간 상태에서의 유용한 피드백을 제공 -> 학습 과정이 더 빠르게 수렴하도록 도움
- 이는 에이전트가 보다 빨리 최적의 정책을 학습할 수 있게
- 탐색 공간 가지치기 :
3.3 Multi-level Reasoning Path Extraction
- cascading Actor-Critic의 출력을 기반으로 다중 레벨 추론 경로를 추출함.
- 다중 레벨 경로에서 각 개념 \(c_{t}^{0\sim L}\)(t<T)는 KG의 어느 레벨에도 속할 수 있음.
단일 레벨 경로랑 비교할 때, 다중레벨 경로는 상요자 관심사를 정확하게 표현하는데 필수적인 유연성을 제공함.
우리는 2가지 단계로 다중레벨 경로 \(\tau_{u}^{0\sim L}\)를 추출함 :
- 다중 레벨 가치 함수 학습( Multi-level Value Function Learning )과 가치 기반 경로 추출( value-based path extraction )
3.3.1 Multi-level Value Function Learning
다중 레벨 가치 함수 \(V^{0\sim L}\) 을 학습해 다중 레벨 상태 \(s_{t}^{0\sim L}=(u,c_{t-K}^{0\sim L},r_{t-K+1}\cdot\cdot\cdot,c_{t-1}^{0\sim L},r_{t},c_{t}^{0\sim L})\) 의 예상 보상을 추정함.이는 단일 레벨 \(l\)에서의 가치 함수 학습 방법을 확장함으로써 달성됨. 구체적으로, 각 반복에서 다음을 수행.
- \(\mathcal{P}^{0}\) 및 \(\pi^{0}\)에 따라 \(\mathbf{M}^{0}\) 에서 \(\left(s_{t}^{0},a_{t},s_{t+1}^{0},{\mathcal{R}}^{0}(s_{t}^{0},a_{t})\right)\) 샘플링
- \(s^{0}_{t+1}\)의 개념을 무작위로 \(L\) 수준 중 하나에 매핑해 다중 레벨 샘플 \(\left(s_{t}^{0\sim L},a_{t},s_{t+1}^{0\sim L},\mathcal{R}^{0}(s_{t}^{0},a_{t})\right)\) 생성
- \(J_{V^{0\sim L}}\,+\,J_{V^{0\sim L}}^{\prime}\) 최소화
- $$J_{V^{0\sim L}}=||\mathcal{R}^{0}(s_{t}^{0},a_{t})+\mathcal{F}^{0}(s_{t}^{0},s_{t+1}^{0})+V^{0\sim L}(s_{t+1}^{0\sim L})-V^{0\sim L}(s_{t}^{0\sim L})||^{2}$$
$$J_{V^{0\sim L}}^{\prime}=\vert\vert V^{0\sim L}(s_{t+1}^{0\sim L})-V^{0}(s_{t+1}^{0})\vert\vert^{2} \quad\quad (12)$$- \( J_{V^{0\sim L}} \)와 \( J_{V^{0\sim L}} \) : 각각 보상 \(\textstyle{\mathcal{R}}^{0}\) 및 학습된 가치 함수 \(V^{0}\)를 사용해 \(V^{0\sim L}\)의 모델 매개변수를 최적화 함.
- $$J_{V^{0\sim L}}=||\mathcal{R}^{0}(s_{t}^{0},a_{t})+\mathcal{F}^{0}(s_{t}^{0},s_{t+1}^{0})+V^{0\sim L}(s_{t+1}^{0\sim L})-V^{0\sim L}(s_{t}^{0\sim L})||^{2}$$
- Interpretation
- \( V^{0\sim L} \)의 상태 공간 \(S^{0}{^{\sim L}}\)은 \(S^0\)의 상위 집합임. \(S^0\)인 bottom-level 상태 경우 , \( V^{0\sim L} \) 은 \(V^{0}\)과 같음. 반면 더 높은 수준에서는 \( V^{0\sim L} \)(다중레벨 보상 함수 : 여러 레벨의 보상을 추정.다양한 레벨의 출력들을 결합해 사용자의 관심사를 더 잘 반영) 이 \(\pi^0\)의 다양한 출력을 결합할 추가 기회를 제공하여, \(\pi^0\)가 하위 레벨에서 진정한 사용자 관심사를 포착하지 못하더라도 여전히 좋은 결과를 낼 수 있음.

3.3.2 Value-based Path Extraction
주어진 상태 \(S_{t-1}^{0\sim L}\) 에서, 우리는 \(S_{t-1}^{0\sim L}\) 로부터의 예상 보상을 최대화함으로써 다음 상태인 \(S_{t}^{0\sim L}\) 을 선택함 :
\[argmax_{S_{t}^{0\sim L}}\ \hat{\mathcal{R}}(s_{t-1}^{0\sim L},s_{t}^{0\sim L})+V^{0\sim L}(s_{t}^{0\sim L})\quad\quad(13)\]
- \({\hat{R}}(s_{t-1}^{0\sim L},s_{t}^{0\sim L})\) : 상태 \(S_{t-1}^{0\sim L}\) 에서 \(S_{t}^{0\sim L}\)을 선택한 것에 대한 예상 보상
- 실제 보상은 테스트 중에 사용할 수 없어서 여기서 사용되지 않는다.
- 경로 추론에서는 오로지 종료 보상만 존재. 따라서 \(t\neq T\)일때 \({\hat{R}}(s_{t-1}^{0\sim L},s_{t}^{0\sim L})\) 는 0이다.
- 종료 상태에서, \({\hat{R}}(s_{T-1}^{0\sim L},s_{T}^{0\sim L})\)는 경로의 끝에서 항목 \(v_{u}=c_{T}^{0\sim L}\)를 사용자가 얼마나 좋아하는지를 추정하며, 이는 어떠한 추천 모델이라도 될 수 있음.
이 논문에서는 \({\hat{R}}{(s_{t-1}^{0\sim L},s_{t}^{0\sim L})}\)를 [30]의 scoring 함수로 설정함.
- 상태 \( s_{T}^{0\sim L} \)을 순차적으로 선택 -> 추론 경로 \(\tau_{u}^{0\sim L}\)를 얻으며, 여기서 t번쨰 hop은 \( s_{T}^{0\sim L} \)의 \((r_{t},c_{t}^{0-L})\)로 구성됨.
- 국소 최적값을 피하기 위해, 시간 t에서 상위 \(N_t\) 상태를 유지함. 이는 \(\textstyle\prod_{t=1}^{T}N_{t}\) 후보 경로를 얻을 수 있게 함.이 후보들 중에서 상위 경로들이 식(13)에 따라 선택됨.
1. 국소 최소값(Local Minimum)을 피하기 위해 상위 상태 유지
- 국소 최소값이란?
- 국소 최소값은 전체 최적값(global optimum)이 아닌 특정 부분에서의 최적값을 의미합니다. 즉, 전체적으로 더 나은 결과를 얻을 수 있는데, 특정 부분에서 멈추어 더 나은 결과를 찾지 못하는 상황을 말합니다.
- 상위 \(N_t\) 상태 유지:
- 경로 추출 과정에서 각 시간 t에서 상위 \(N_t\) 개의 상태를 유지합니다.
- 예를 들어, \(N_t\)=5라고 하면, 시간 t에서 가장 좋은 5개의 상태를 유지하는 것입니다.
- 이렇게 하면 국소 최소값에 빠지지 않고 더 나은 경로를 탐색할 수 있습니다.
2. 후보 경로 생성
- 후보 경로:
- 각 시간 t에서 상위 \(N_t\) 개의 상태를 유지하면, 시간 까지의 모든 경로를 조합하면 후보 경로의 수가 \(\textstyle\prod_{t=1}^{T}N_{t}\) 가 됩니다.
- 예를 들어, 시간 T=3, 각 시간에서 \(N_t\) =5라고 하면, 후보 경로의 수는 5×5×5=1255개가 됩니다.
3. 상위 경로 선택
- Eq. (13):
- Eq. (13)은 "argmax" 식으로 주어진 상태에서 다음 상태를 선택하는 방법을 설명하는 식입니다. (위의 설명 참고)
- 이 식에 따라 각 후보 경로 중에서 가장 좋은 경로를 선택합니다.
4. 추천 항목 결정
- 추천 항목 집합 \(V_u\) :
- 최종적으로 선택된 경로의 끝에 있는 항목 집합 \(V_u\) 는 사용자 u에게 추천됩니다.
- 예를 들어, Alice가 립스틱을 구매한 기록이 있고, 이 정보를 바탕으로 파운데이션을 추천하게 될 경우, \(V_u\) 는 "파운데이션"과 같은 항목이 됩니다.
- 추출된 경로의 끝에 있는 항목 집한 \(V_u\)는 사용자 \(u\)에게 추천됨.
'kdd > knowledge graph 논문 리뷰' 카테고리의 다른 글
| [강화학습]PGPR과 ReMR을 읽기 위한 base (0) | 2024.07.28 |
|---|---|
| [KG_2019]KGAT: Knowledge Graph Attention Network for Recommendation (0) | 2024.07.24 |
| [KG]PGPR을 읽고 ReMR을 읽으면서 느낀 둘 사이의 연관성 (2) | 2024.07.22 |
| [KG_2019]KPRN(Explainable Reasoning over Knowledge Graphs for Recommendation) (1) | 2024.07.22 |
| [KG_2019]PGPR(Reinforcement Knowledge Graph Reasoning forExplainable Recommendation) (8) | 2024.07.21 |


